Loki protocol supports optional `metadata` object for each ingested line. It's added as 3rd field at the (ts,msg,metadata) tuple. Previously, loki request json parsers rejected log line if tuple size != 2.
This commit allows optional tuple field. It parses it as json object and adds it as log metadata fields to the log message stream.
related issue:
https://github.com/VictoriaMetrics/VictoriaMetrics/issues/7431
---------
Co-authored-by: f41gh7 <nik@victoriametrics.com>
### Describe Your Changes
Christmas is early and you get the first present in the shape of
spelling fixes.
Sorry for the big amount :)
### Checklist
- [x] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
In this case the _msg field is set to the value specified in the -defaultMsgValue command-line flag.
This should simplify first-time migration to VictoriaLogs from other systems.
This msy be useful when ingesting logs from different sources, which store the log message in different fields.
For example, `_msg_field=message,event.data,some_field` will get log message from the first non-empty field:
`message`, `event.data` and `some_field`.
If the number of output (bloom, values) shards is zero, then this may lead to panic
as shown at https://github.com/VictoriaMetrics/VictoriaMetrics/issues/7391 .
This panic may happen when parts with only constant fields with distinct values are merged into
output part with non-constant fields, which should be written to (bloom, values) shards.
This allows reducing the amounts of data, which must be read during queries over logs with big number of fields (aka "wide events").
This, in turn, improves query performance when the data, which needs to be scanned during the query, doesn't fit OS page cache.
This improves performance of `field_values` pipe when it is applied to large number of data blocks.
This also improves performance of /select/logsql/field_values HTTP API.
### Describe Your Changes
Fixes issues with incorrect updating of query and limit fields, and
resolves the problem where the display tab resets.
Related issue: #7279 and #7290
### Checklist
The following checks are **mandatory**:
- [ ] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
---------
Signed-off-by: hagen1778 <roman@victoriametrics.com>
Co-authored-by: Zakhar Bessarab <z.bessarab@victoriametrics.com>
### Describe Your Changes
**Added ability to hide the hits chart**
- Users can now hide or show the hits chart by clicking the "eye" icon
located in the upper-right corner of the chart.
- When the chart is hidden, it will stop sending requests to
`/select/logsql/hits`.
- Upon displaying the chart again, it will automatically refresh. If a
relative time range is set, the chart will update according to the time
period of the logs currently being displayed.
**Hits chart visible:**
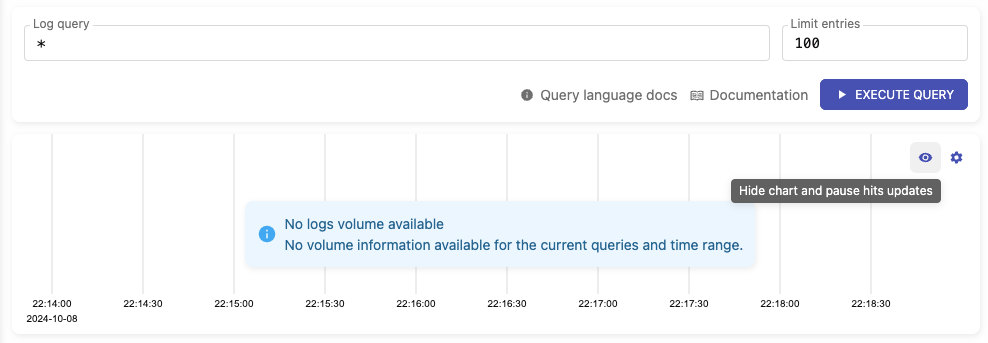
**Hits chart hidden:**

Related issue: #7117
### Checklist
The following checks are **mandatory**:
- [ ] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
Co-authored-by: Aliaksandr Valialkin <valyala@victoriametrics.com>
### Describe Your Changes
Fixed the display of hits chart in VictoriaLogs.
See #7133
### Checklist
The following checks are **mandatory**:
- [ ] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
Unpack the full columnsHeader block instead of unpacking meta-information per each individual column
when the query, which selects all the columns, is executed. This improves performance when scanning
logs with big number of fields.
- Use parallel merge of per-CPU shard results. This improves merge performance on multi-CPU systems.
- Use topN heap sort of per-shard results. This improves performance when results contain millions of entries.
1. Verify if field in [fields
pipe](https://docs.victoriametrics.com/victorialogs/logsql/#fields-pipe)
exists. If not, it generates a metric with illegal float value "" for
prometheus metrics protocol.
2. check if multiple time range filters produce conflicted query time
range, for instance:
```
query: _time: 5m | stats count(),
start:2024-10-08T10:00:00.806Z,
end: 2024-10-08T12:00:00.806Z,
time: 2024-10-10T10:02:59.806Z
```
must give no result due to invalid final time range.
---------
Co-authored-by: Aliaksandr Valialkin <valyala@victoriametrics.com>
It has been appeared that VictoriaLogs is frequently used for collecting logs with tens of fields.
For example, standard Kuberntes setup on top of Filebeat generates more than 20 fields per each log.
Such logs are also known as "wide events".
The previous storage format was optimized for logs with a few fields. When at least a single field
was referenced in the query, then the all the meta-information about all the log fields was unpacked
and parsed per each scanned block during the query. This could require a lot of additional disk IO
and CPU time when logs contain many fields. Resolve this issue by providing an (field -> metainfo_offset)
index per each field in every data block. This index allows reading and extracting only the needed
metainfo for fields used in the query. This index is stored in columnsHeaderIndexFilename ( columns_header_index.bin ).
This allows increasing performance for queries over wide events by 10x and more.
Another issue was that the data for bloom filters and field values across all the log fields except of _msg
was intermixed in two files - fieldBloomFilename ( field_bloom.bin ) and fieldValuesFilename ( field_values.bin ).
This could result in huge disk read IO overhead when some small field was referred in the query,
since the Operating System usually reads more data than requested. It reads the data from disk
in at least 4KiB blocks (usually the block size is much bigger in the range 64KiB - 512KiB).
So, if 512-byte bloom filter or values' block is read from the file, then the Operating System
reads up to 512KiB of data from disk, which results in 1000x disk read IO overhead. This overhead isn't visible
for recently accessed data, since this data is usually stored in RAM (aka Operating System page cache),
but this overhead may become very annoying when performing the query over large volumes of data
which isn't present in OS page cache.
The solution for this issue is to split bloom filters and field values across multiple shards.
This reduces the worst-case disk read IO overhead by at least Nx where N is the number of shards,
while the disk read IO overhead is completely removed in best case when the number of columns doesn't exceed N.
Currently the number of shards is 8 - see bloomValuesShardsCount . This solution increases
performance for queries over large volumes of newly ingested data by up to 1000x.
The new storage format is versioned as v1, while the old storage format is version as v0.
It is stored in the partHeader.FormatVersion.
Parts with the old storage format are converted into parts with the new storage format during background merge.
It is possible to force merge by querying /internal/force_merge HTTP endpoint - see https://docs.victoriametrics.com/victorialogs/#forced-merge .
### Describe Your Changes
Fix `Alert` component to prevent it from overflowing the screen when
displaying long messages.
Related issue: #7207
### Checklist
The following checks are **mandatory**:
- [x] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
---------
Signed-off-by: Zakhar Bessarab <z.bessarab@victoriametrics.com>
Signed-off-by: hagen1778 <roman@victoriametrics.com>
Co-authored-by: hagen1778 <roman@victoriametrics.com>
### Describe Your Changes
- Added functionality to cancel running queries on the Explore Logs and
Query pages.
- The loader was changed from a spinner to a top bar within the block.
This still indicates loading, but solves the issue of the spinner
"flickering," especially during graph dragging.
Related issue: #7097https://github.com/user-attachments/assets/98e59aeb-905b-4b9d-bbb2-688223b22a82
### Checklist
The following checks are **mandatory**:
- [ ] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
Empty fields are treated as non-existing fields by VictoriaLogs data model.
So there is no sense in returning empty fields in query results, since they may mislead and confuse users.
s.partitions can be changed when new partition is registered or when old partition is dropped.
This could lead to data races and panics when s.partitions slice is accessed by concurrently executed queries.
The fix is to make a copy of the selected partitions under s.partitionsLock before performing the query.