…ides ### Describe Your Changes Please provide a brief description of the changes you made. Be as specific as possible to help others understand the purpose and impact of your modifications. ### Checklist The following checks are **mandatory**: - [ ] My change adheres [VictoriaMetrics contributing guidelines](https://docs.victoriametrics.com/contributing/). Signed-off-by: hagen1778 <roman@victoriametrics.com> |
||
|---|---|---|
| .. | ||
| anomaly-detection | ||
| changelog | ||
| data-ingestion | ||
| guides | ||
| helm | ||
| keyConcepts | ||
| operator | ||
| VictoriaLogs | ||
| victoriametrics-cloud | ||
| _index.md | ||
| Articles.md | ||
| BestPractices.md | ||
| CaseStudies.md | ||
| Cluster-VictoriaMetrics.md | ||
| Cluster-VictoriaMetrics_cluster-scheme.webp | ||
| CONTRIBUTING.md | ||
| enterprise.md | ||
| ExtendedPromQL.md | ||
| FAQ.md | ||
| goals.md | ||
| grafana-datasource-prometheus.webp | ||
| logo.webp | ||
| logo_white.webp | ||
| LTS-releases.md | ||
| Makefile | ||
| MetricsQL.md | ||
| PerTenantStatistic-stats.webp | ||
| PerTenantStatistic.md | ||
| provision_datasources.webp | ||
| Quick-Start.md | ||
| README.md | ||
| README_sending_DD_metrics_to_VM.webp | ||
| README_sending_DD_metrics_to_VM_and_DD.webp | ||
| relabeling.md | ||
| Release-Guide.md | ||
| Release-Guide_helm-release.webp | ||
| scrape_config_examples.md | ||
| sd_configs.md | ||
| Single-server-VictoriaMetrics.md | ||
| stream-aggregation-check-avg.webp | ||
| stream-aggregation-check-increase.webp | ||
| stream-aggregation-check-max.webp | ||
| stream-aggregation-check-min.webp | ||
| stream-aggregation-check-stdvar.webp | ||
| stream-aggregation-check-sum-samples.webp | ||
| stream-aggregation-check-total-reset.webp | ||
| stream-aggregation-check-total.webp | ||
| stream-aggregation.md | ||
| Troubleshooting.md | ||
| url-examples.md | ||
| victoriametrics-datasource.md | ||
| vmagent.md | ||
| vmagent.webp | ||
| vmalert-tool.md | ||
| vmalert.md | ||
| vmalert_cluster.excalidraw | ||
| vmalert_cluster.webp | ||
| vmalert_ha.excalidraw | ||
| vmalert_ha.webp | ||
| vmalert_multicluster.excalidraw | ||
| vmalert_multicluster.webp | ||
| vmalert_multiple_rw.excalidraw | ||
| vmalert_multiple_rw.webp | ||
| vmalert_single.excalidraw | ||
| vmalert_single.webp | ||
| vmalert_state.webp | ||
| vmalert_ts_data_delay.gif | ||
| vmalert_ts_normal.gif | ||
| vmauth.md | ||
| vmbackup.md | ||
| vmbackupmanager.md | ||
| vmbackupmanager_latest_folder.webp | ||
| vmbackupmanager_root_folder.webp | ||
| vmbackupmanager_rp_daily_1.webp | ||
| vmbackupmanager_rp_daily_2.webp | ||
| vmctl.md | ||
| vmgateway-access-control.webp | ||
| vmgateway-overview.webp | ||
| vmgateway-rate-limiting.webp | ||
| vmgateway.md | ||
| vmrestore.md | ||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


![]()

![]()
![]()
VictoriaMetrics is a fast, cost-effective and scalable monitoring solution and time series database. See case studies for VictoriaMetrics.
VictoriaMetrics is available in binary releases, Docker images and source code.
Documentation for the cluster version of VictoriaMetrics is available here.
Learn more about key concepts of VictoriaMetrics and follow the quick start guide for a better experience.
If you have questions about VictoriaMetrics, then feel free asking them in the VictoriaMetrics community Slack chat, you can join it via Slack Inviter.
Contact us if you need enterprise support for VictoriaMetrics. See features available in enterprise package. Enterprise binaries can be downloaded and evaluated for free from the releases page. You can also request a free trial license.
VictoriaMetrics is developed at a fast pace, so it is recommended to check the CHANGELOG periodically, and to perform regular upgrades.
VictoriaMetrics enterprise provides long-term support lines of releases (LTS releases) - see these docs.
VictoriaMetrics has achieved security certifications for Database Software Development and Software-Based Monitoring Services. We apply strict security measures in everything we do. See Security page for more details.
Prominent features
VictoriaMetrics has the following prominent features:
- It can be used as long-term storage for Prometheus. See these docs for details.
- It can be used as a drop-in replacement for Prometheus in Grafana, because it supports the Prometheus querying API.
- It can be used as a drop-in replacement for Graphite in Grafana, because it supports the Graphite API. VictoriaMetrics allows reducing infrastructure costs by more than 10x comparing to Graphite - see this case study.
- It is easy to setup and operate:
- VictoriaMetrics consists of a single small executable without external dependencies.
- All the configuration is done via explicit command-line flags with reasonable defaults.
- All the data is stored in a single directory specified by the
-storageDataPathcommand-line flag. - Easy and fast backups from instant snapshots can be done with vmbackup / vmrestore tools. See this article for more details.
- It implements a PromQL-like query language - MetricsQL, which provides improved functionality on top of PromQL.
- It provides a global query view. Multiple Prometheus instances or any other data sources may ingest data into VictoriaMetrics. Later this data may be queried via a single query.
- It provides high performance and good vertical and horizontal scalability for both data ingestion and data querying. It outperforms InfluxDB and TimescaleDB by up to 20x.
- It uses 10x less RAM than InfluxDB and up to 7x less RAM than Prometheus, Thanos or Cortex when dealing with millions of unique time series (aka high cardinality).
- It is optimized for time series with high churn rate.
- It provides high data compression: up to 70x more data points may be stored into limited storage compared with TimescaleDB according to these benchmarks, and up to 7x less storage space is required compared to Prometheus, Thanos or Cortex. according to this benchmark.
- It is optimized for storage with high-latency IO and low IOPS (HDD and network storage in AWS, Google Cloud, Microsoft Azure, etc). See disk IO graphs from these benchmarks.
- A single-node VictoriaMetrics may substitute moderately sized clusters built with competing solutions such as Thanos, M3DB, Cortex, InfluxDB or TimescaleDB. See vertical scalability benchmarks, comparing Thanos to VictoriaMetrics cluster and Remote Write Storage Wars talk from PromCon 2019.
- It protects the storage from data corruption on unclean shutdown (i.e. OOM, hardware reset or
kill -9) thanks to the storage architecture. - It supports metrics scraping, ingestion and backfilling via the following protocols:
- Metrics scraping from Prometheus exporters.
- Prometheus remote write API.
- Prometheus exposition format.
- InfluxDB line protocol over HTTP, TCP and UDP.
- Graphite plaintext protocol with tags.
- OpenTSDB put message.
- HTTP OpenTSDB /api/put requests.
- JSON line format.
- Arbitrary CSV data.
- Native binary format.
- DataDog agent or DogStatsD.
- NewRelic infrastructure agent.
- OpenTelemetry metrics format.
- It supports powerful stream aggregation, which can be used as a statsd alternative.
- It supports metrics relabeling.
- It can deal with high cardinality issues and high churn rate issues via series limiter.
- It ideally works with big amounts of time series data from APM, Kubernetes, IoT sensors, connected cars, industrial telemetry, financial data and various Enterprise workloads.
- It has an open source cluster version.
- It can store data on NFS-based storages such as Amazon EFS and Google Filestore.
See case studies for VictoriaMetrics and various Articles about VictoriaMetrics.
Components
VictoriaMetrics ecosystem contains the following components additionally to single-node VictoriaMetrics:
- vmagent - lightweight agent for receiving metrics via pull-based and push-based protocols, transforming and sending them to the configured Prometheus-compatible remote storage systems such as VictoriaMetrics.
- vmalert - a service for processing Prometheus-compatible alerting and recording rules.
- vmalert-tool - a tool for validating alerting and recording rules.
- vmauth - authorization proxy and load balancer optimized for VictoriaMetrics products.
- vmgateway - authorization proxy with per-tenant rate limiting capabilities.
- vmctl - a tool for migrating and copying data between different storage systems for metrics.
- vmbackup, vmrestore and vmbackupmanager - tools for creating backups and restoring from backups for VictoriaMetrics data.
vminsert,vmselectandvmstorage- components of VictoriaMetrics cluster.- VictoriaLogs - user-friendly cost-efficient database for logs.
Operation
Install
To quickly try VictoriaMetrics, just download the VictoriaMetrics executable or Docker image and start it with the desired command-line flags. See also QuickStart guide for additional information.
VictoriaMetrics can also be installed via these installation methods:
- Helm charts for single-node and cluster versions of VictoriaMetrics.
- Kubernetes operator for VictoriaMetrics.
- Ansible role for installing cluster VictoriaMetrics (by VictoriaMetrics).
- Ansible role for installing cluster VictoriaMetrics (by community).
- Ansible role for installing single-node VictoriaMetrics (by community).
How to start VictoriaMetrics
The following command-line flags are used the most:
-storageDataPath- VictoriaMetrics stores all the data in this directory. The default path isvictoria-metrics-datain the current working directory.-retentionPeriod- retention for stored data. Older data is automatically deleted. Default retention is 1 month (31 days). The minimum retention period is 24h or 1d. See these docs for more details.
Other flags have good enough default values, so set them only if you really need to. Pass -help to see all the available flags with description and default values.
The following docs may be useful during initial VictoriaMetrics setup:
- How to set up scraping of Prometheus-compatible targets
- How to ingest data to VictoriaMetrics
- How to set up Prometheus to write data to VictoriaMetrics
- How to query VictoriaMetrics via Grafana
- How to query VictoriaMetrics via Graphite API
- How to handle alerts
VictoriaMetrics accepts Prometheus querying API requests on port 8428 by default.
It is recommended setting up monitoring for VictoriaMetrics.
Environment variables
All the VictoriaMetrics components allow referring environment variables in yaml configuration files (such as -promscrape.config)
and in command-line flags via %{ENV_VAR} syntax.
For example, -metricsAuthKey=%{METRICS_AUTH_KEY} is automatically expanded to -metricsAuthKey=top-secret
if METRICS_AUTH_KEY=top-secret environment variable exists at VictoriaMetrics startup.
This expansion is performed by VictoriaMetrics itself.
VictoriaMetrics recursively expands %{ENV_VAR} references in environment variables on startup.
For example, FOO=%{BAR} environment variable is expanded to FOO=abc if BAR=a%{BAZ} and BAZ=bc.
Additionally, all the VictoriaMetrics components allow setting flag values via environment variables according to these rules:
- The
-envflag.enableflag must be set. - Each
.char in flag name must be substituted with_(for example-insert.maxQueueDuration <duration>will translate toinsert_maxQueueDuration=<duration>). - For repeating flags an alternative syntax can be used by joining the different values into one using
,char as separator (for example-storageNode <nodeA> -storageNode <nodeB>will translate tostorageNode=<nodeA>,<nodeB>). - Environment var prefix can be set via
-envflag.prefixflag. For instance, if-envflag.prefix=VM_, then env vars must be prepended withVM_.
Running as Windows service
In order to run VictoriaMetrics as a Windows service it is required to create a service configuration for WinSW and then install it as a service according to the following guide:
-
Create a service configuration:
<service> <id>VictoriaMetrics</id> <name>VictoriaMetrics</name> <description>VictoriaMetrics</description> <executable>%BASE%\victoria-metrics-windows-amd64-prod.exe"</executable> <onfailure action="restart" delay="10 sec"/> <onfailure action="restart" delay="20 sec"/> <resetfailure>1 hour</resetfailure> <arguments>-envflag.enable</arguments> <priority>Normal</priority> <stoptimeout>15 sec</stoptimeout> <stopparentprocessfirst>true</stopparentprocessfirst> <startmode>Automatic</startmode> <waithint>15 sec</waithint> <sleeptime>1 sec</sleeptime> <logpath>%BASE%\logs</logpath> <log mode="roll"> <sizeThreshold>10240</sizeThreshold> <keepFiles>8</keepFiles> </log> <env name="loggerFormat" value="json" /> <env name="loggerOutput" value="stderr" /> <env name="promscrape_config" value="C:\Program Files\victoria-metrics\promscrape.yml" /> </service> -
Install WinSW by following this documentation.
-
Install VictoriaMetrics as a service by running the following from elevated PowerShell:
winsw install VictoriaMetrics.xml Get-Service VictoriaMetrics | Start-Service
See this issue for more details.
Prometheus setup
Add the following lines to Prometheus config file (it is usually located at /etc/prometheus/prometheus.yml) in order to send data to VictoriaMetrics:
remote_write:
- url: http://<victoriametrics-addr>:8428/api/v1/write
Substitute <victoriametrics-addr> with hostname or IP address of VictoriaMetrics.
Then apply new config via the following command:
kill -HUP `pidof prometheus`
Prometheus writes incoming data to local storage and replicates it to remote storage in parallel.
This means that data remains available in local storage for --storage.tsdb.retention.time duration
even if remote storage is unavailable.
If you plan sending data to VictoriaMetrics from multiple Prometheus instances, then add the following lines into global section
of Prometheus config:
global:
external_labels:
datacenter: dc-123
This instructs Prometheus to add datacenter=dc-123 label to each sample before sending it to remote storage.
The label name can be arbitrary - datacenter is just an example. The label value must be unique
across Prometheus instances, so time series could be filtered and grouped by this label.
For highly loaded Prometheus instances (200k+ samples per second) the following tuning may be applied:
remote_write:
- url: http://<victoriametrics-addr>:8428/api/v1/write
queue_config:
max_samples_per_send: 10000
capacity: 20000
max_shards: 30
Using remote write increases memory usage for Prometheus by up to ~25%. If you are experiencing issues with
too high memory consumption of Prometheus, then try to lower max_samples_per_send and capacity params.
Keep in mind that these two params are tightly connected.
Read more about tuning remote write for Prometheus here.
It is recommended upgrading Prometheus to v2.12.0 or newer,
since previous versions may have issues with remote_write.
Take a look also at vmagent and vmalert, which can be used as faster and less resource-hungry alternative to Prometheus.
Grafana setup
Create Prometheus datasource in Grafana with the following url:
http://<victoriametrics-addr>:8428
Substitute <victoriametrics-addr> with the hostname or IP address of VictoriaMetrics.
In the "Type and version" section it is recommended to set the type to "Prometheus" and the version to at least "2.24.x":
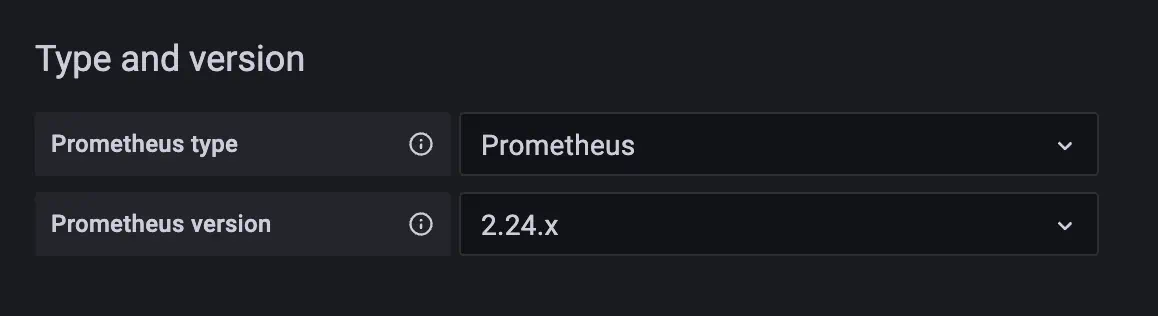
This allows Grafana to use a more efficient API to get label values.
Then build graphs and dashboards for the created datasource using PromQL or MetricsQL.
Alternatively, use VictoriaMetrics datasource plugin with support of extra features. See more in description.
Creating a datasource may require specific permissions. If you don't see an option to create a data source - try contacting system administrator.
Grafana playground is available for viewing at our sandbox.
How to upgrade VictoriaMetrics
VictoriaMetrics is developed at a fast pace, so it is recommended periodically checking the CHANGELOG page and performing regular upgrades.
It is safe upgrading VictoriaMetrics to new versions unless release notes say otherwise. It is safe skipping multiple versions during the upgrade unless release notes say otherwise. It is recommended performing regular upgrades to the latest version, since it may contain important bug fixes, performance optimizations or new features.
It is also safe downgrading to older versions unless release notes say otherwise.
The following steps must be performed during the upgrade / downgrade procedure:
- Send
SIGINTsignal to VictoriaMetrics process in order to gracefully stop it. See how to send signals to processes. - Wait until the process stops. This can take a few seconds.
- Start the upgraded VictoriaMetrics.
Prometheus doesn't drop data during VictoriaMetrics restart. See this article for details. The same applies also to vmagent.
vmui
VictoriaMetrics provides UI for query troubleshooting and exploration. The UI is available at http://victoriametrics:8428/vmui
(or at http://<vmselect>:8481/select/<accountID>/vmui/ in cluster version of VictoriaMetrics).
The UI allows exploring query results via graphs and tables. It also provides the following features:
- Explore:
- Metrics explorer - automatically builds graphs for selected metrics;
- Cardinality explorer - stats about existing metrics in TSDB;
- Top queries - shows most frequently executed queries;
- Active queries - shows currently executed queries;
- Tools:
- Trace analyzer - playground for loading query traces in JSON format;
- Query analyzer - playground for loading query results and traces in JSON format. See
Export querybutton below; - WITH expressions playground - test how WITH expressions work;
- Metric relabel debugger - playground for relabeling configs.
- Downsampling filters debugger - playground for relabeling configs.
- Retention filters debugger - playground for relabeling configs.
VMUI provides auto-completion for MetricsQL functions, metric names, label names and label values. The auto-completion can be enabled
by checking the Autocomplete toggle. When the auto-completion is disabled, it can still be triggered for the current cursor position by pressing ctrl+space.
VMUI automatically switches from graph view to heatmap view when the query returns histogram buckets (both Prometheus histograms and VictoriaMetrics histograms are supported). Try, for example, this query.
Graphs in vmui support scrolling and zooming:
- Select the needed time range on the graph in order to zoom in into the selected time range. Hold
ctrl(orcmdon MacOS) and scroll down in order to zoom out. - Hold
ctrl(orcmdon MacOS) and scroll up in order to zoom in the area under cursor. - Hold
ctrl(orcmdon MacOS) and drag the graph to the left / right in order to move the displayed time range into the future / past.
Query history can be navigated by holding Ctrl (or Cmd on MacOS) and pressing up or down arrows on the keyboard while the cursor is located in the query input field.
Multi-line queries can be entered by pressing Shift-Enter in query input field.
When querying the backfilled data
or during query troubleshooting,
it may be useful disabling response cache by clicking Disable cache checkbox.
VMUI automatically adjusts the interval between datapoints on the graph depending on the horizontal resolution and on the selected time range.
The step value can be customized by changing Step value input.
VMUI allows investigating correlations between multiple queries on the same graph. Just click Add Query button,
enter an additional query in the newly appeared input field and press Enter.
Results for all the queries are displayed simultaneously on the same graph.
Graphs for a particular query can be temporarily hidden by clicking the eye icon on the right side of the input field.
When the eye icon is clicked while holding the ctrl key, then query results for the rest of queries become hidden
except of the current query results.
VMUI allows sharing query and trace results by clicking on
Export query button in top right corner of the graph area. The query and trace will be exported as a file that later
can be loaded in VMUI via Query Analyzer tool.
See the example VMUI at VictoriaMetrics playground.
Top queries
VMUI provides top queries tab, which can help determining the following query types:
- the most frequently executed queries;
- queries with the biggest average execution duration;
- queries that took the most summary time for execution.
This information is obtained from the /api/v1/status/top_queries HTTP endpoint.
Active queries
VMUI provides active queries tab, which shows currently execute queries.
It provides the following information per each query:
- The query itself, together with the time range and step args passed to /api/v1/query_range.
- The duration of the query execution.
- The client address, who initiated the query execution.
This information is obtained from the /api/v1/status/active_queries HTTP endpoint.
Metrics explorer
VMUI provides an ability to explore metrics exported by a particular job / instance in the following way:
- Open the
vmuiathttp://victoriametrics:8428/vmui/. - Click the
Explore Prometheus metricstab. - Select the
jobyou want to explore. - Optionally select the
instancefor the selected job to explore. - Select metrics you want to explore and compare.
It is possible to change the selected time range for the graphs in the top right corner.
Cardinality explorer
VictoriaMetrics provides an ability to explore time series cardinality at Explore cardinality tab in vmui in the following ways:
- To identify metric names with the highest number of series.
- To identify labels with the highest number of series.
- To identify values with the highest number of series for the selected label (aka
focusLabel). - To identify label=name pairs with the highest number of series.
- To identify labels with the highest number of unique values. Note that cluster version of VictoriaMetrics may show lower than expected number of unique label values for labels with small number of unique values. This is because of implementation limits.
By default, cardinality explorer analyzes time series for the current date. It provides the ability to select different day at the top right corner. By default, all the time series for the selected date are analyzed. It is possible to narrow down the analysis to series matching the specified series selector.
Cardinality explorer is built on top of /api/v1/status/tsdb.
See cardinality explorer playground. See the example of using the cardinality explorer here.
Cardinality explorer statistic inaccuracy
In cluster version of VictoriaMetrics each vmstorage tracks the stored time series individually. vmselect requests stats via /api/v1/status/tsdb API from each vmstorage node and merges the results by summing per-series stats. This may lead to inflated values when samples for the same time series are spread across multiple vmstorage nodes due to replication or rerouting.
How to apply new config to VictoriaMetrics
VictoriaMetrics is configured via command-line flags, so it must be restarted when new command-line flags should be applied:
- Send
SIGINTsignal to VictoriaMetrics process in order to gracefully stop it. - Wait until the process stops. This can take a few seconds.
- Start VictoriaMetrics with the new command-line flags.
Prometheus doesn't drop data during VictoriaMetrics restart. See this article for details. The same applies also to vmagent.
How to scrape Prometheus exporters such as node-exporter
VictoriaMetrics can be used as drop-in replacement for Prometheus for scraping targets configured in prometheus.yml config file
according to the specification.
Just set -promscrape.config command-line flag to the path to prometheus.yml config - and VictoriaMetrics should start scraping the configured targets.
If the provided configuration file contains unsupported options,
then either delete them from the file or just pass -promscrape.config.strictParse=false command-line flag to VictoriaMetrics, so it will ignore unsupported options.
The file pointed by -promscrape.config may contain %{ENV_VAR} placeholders, which are substituted by the corresponding ENV_VAR environment variable values.
See also:
VictoriaMetrics also supports importing data in Prometheus exposition format.
See also vmagent, which can be used as drop-in replacement for Prometheus.
How to send data from DataDog agent
VictoriaMetrics accepts data from DataDog agent, DogStatsD and
DataDog Lambda Extension
via "submit metrics" API at /datadog/api/v2/series or via "sketches" API at /datadog/api/beta/sketches.
Sending metrics to VictoriaMetrics
DataDog agent allows configuring destinations for metrics sending via ENV variable DD_DD_URL
or via configuration file in section dd_url.
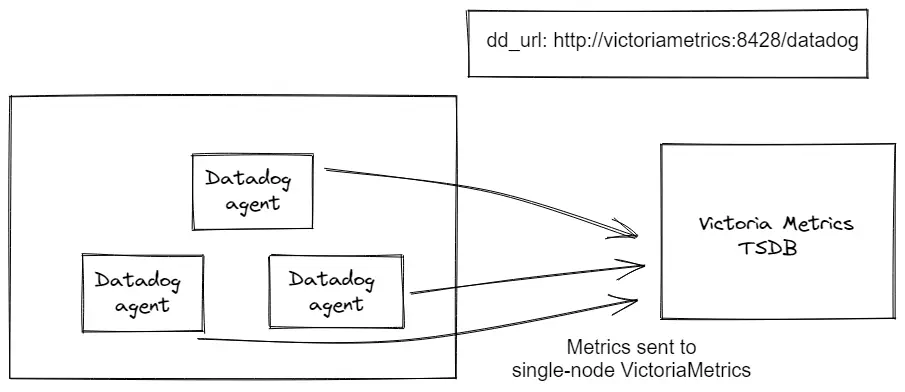
To configure DataDog agent via ENV variable add the following prefix:
DD_DD_URL=http://victoriametrics:8428/datadog
Choose correct URL for VictoriaMetrics here.
To configure DataDog agent via configuration file add the following line:
dd_url: http://victoriametrics:8428/datadog
vmagent also can accept DataDog metrics format. Depending on where vmagent will forward data, pick single-node or cluster URL formats.
Sending metrics to DataDog and VictoriaMetrics
DataDog allows configuring Dual Shipping for metrics
sending via ENV variable DD_ADDITIONAL_ENDPOINTS or via configuration file additional_endpoints.

Run DataDog using the following ENV variable with VictoriaMetrics as additional metrics receiver:
DD_ADDITIONAL_ENDPOINTS='{\"http://victoriametrics:8428/datadog\": [\"apikey\"]}'
Choose correct URL for VictoriaMetrics here.
To configure DataDog Dual Shipping via configuration file add the following line:
additional_endpoints:
"http://victoriametrics:8428/datadog":
- apikey
Send metrics via Serverless DataDog plugin
Disable logs (logs ingestion is not supported by VictoriaMetrics) and set a custom endpoint in serverless.yaml:
custom:
datadog:
enableDDLogs: false # Disabled not supported DD logs
apiKey: fakekey # Set any key, otherwise plugin fails
provider:
environment:
DD_DD_URL: <<vm-url>>/datadog # VictoriaMetrics endpoint for DataDog
Send via cURL
See how to send data to VictoriaMetrics via DataDog "submit metrics" API here.
The imported data can be read via export API.
Additional details
VictoriaMetrics automatically sanitizes metric names for the data ingested via DataDog protocol
according to DataDog metric naming recommendations.
If you need accepting metric names as is without sanitizing, then pass -datadog.sanitizeMetricName=false command-line flag to VictoriaMetrics.
Extra labels may be added to all the written time series by passing extra_label=name=value query args.
For example, /datadog/api/v2/series?extra_label=foo=bar would add {foo="bar"} label to all the ingested metrics.
DataDog agent sends the configured tags to
undocumented endpoint - /datadog/intake. This endpoint isn't supported by VictoriaMetrics yet.
This prevents from adding the configured tags to DataDog agent data sent into VictoriaMetrics.
The workaround is to run a sidecar vmagent alongside every DataDog agent,
which must run with DD_DD_URL=http://localhost:8429/datadog environment variable.
The sidecar vmagent must be configured with the needed tags via -remoteWrite.label command-line flag and must forward
incoming data with the added tags to a centralized VictoriaMetrics specified via -remoteWrite.url command-line flag.
See these docs for details on how to add labels to metrics at vmagent.
How to send data from InfluxDB-compatible agents such as Telegraf
Use http://<victoriametrics-addr>:8428 URL instead of InfluxDB url in agents' configs.
For instance, put the following lines into Telegraf config, so it sends data to VictoriaMetrics instead of InfluxDB:
[[outputs.influxdb]]
urls = ["http://<victoriametrics-addr>:8428"]
Or in case of http output
[[outputs.http]]
url = "http://<victoriametrics-addr>:8428/influx/write"
data_format = "influx"
non_retryable_statuscodes = [400]
The size of the request sent to VictoriaMetrics's Influx HTTP endpoints is limited by -influx.maxRequestSize (default: 64Mb).
For better ingestion speed and lower memory usage, VM can be switched to stream processing mode by setting Stream-Mode: "1"
HTTP header with each request. Please note, in streaming mode VictoriaMetrics processes workload line-by-line (see -influx.maxLineSize),
it ignores invalid rows (only logs them) and ingests successfully parsed rows. If client cancels the ingestion request
due to timeout or other reasons, it could happen that some lines from the workload were already parsed and ingested.
Another option is to enable TCP and UDP receiver for InfluxDB line protocol via -influxListenAddr command-line flag
and stream plain InfluxDB line protocol data to the configured TCP and/or UDP addresses. TCP and UDP receivers are
only working in streaming mode.
VictoriaMetrics performs the following transformations to the ingested InfluxDB data:
- db query arg is mapped into
dblabel value unlessdbtag exists in the InfluxDB line. Thedblabel name can be overridden via-influxDBLabelcommand-line flag. If more strict data isolation is required, read more about multi-tenancy here. - Field names are mapped to time series names prefixed with
{measurement}{separator}value, where{separator}equals to_by default. It can be changed with-influxMeasurementFieldSeparatorcommand-line flag. See also-influxSkipSingleFieldcommand-line flag. If{measurement}is empty or if-influxSkipMeasurementcommand-line flag is set, then time series names correspond to field names. - Field values are mapped to time series values.
- Non-numeric field values are converted to 0.
- Tags are mapped to Prometheus labels as-is.
- If
-usePromCompatibleNamingcommand-line flag is set, then all the metric names and label names are normalized to Prometheus-compatible naming by replacing unsupported chars with_. For example,foo.bar-baz/1metric name or label name is substituted withfoo_bar_baz_1.
For example, the following InfluxDB line:
foo,tag1=value1,tag2=value2 field1=12,field2=40
is converted into the following Prometheus data points:
foo_field1{tag1="value1", tag2="value2"} 12
foo_field2{tag1="value1", tag2="value2"} 40
Example for writing data with InfluxDB line protocol
to local VictoriaMetrics using curl:
curl -d 'measurement,tag1=value1,tag2=value2 field1=123,field2=1.23' -X POST 'http://localhost:8428/write'
An arbitrary number of lines delimited by '\n' (aka newline char) can be sent in a single request. After that the data may be read via /api/v1/export endpoint:
curl -G 'http://localhost:8428/api/v1/export' -d 'match={__name__=~"measurement_.*"}'
The /api/v1/export endpoint should return the following response:
{"metric":{"__name__":"measurement_field1","tag1":"value1","tag2":"value2"},"values":[123],"timestamps":[1560272508147]}
{"metric":{"__name__":"measurement_field2","tag1":"value1","tag2":"value2"},"values":[1.23],"timestamps":[1560272508147]}
Note that InfluxDB line protocol expects timestamps in nanoseconds by default, while VictoriaMetrics stores them with milliseconds precision. It is allowed to ingest timestamps with seconds, microseconds or nanoseconds precision - VictoriaMetrics will automatically convert them to milliseconds.
Extra labels may be added to all the written time series by passing extra_label=name=value query args.
For example, /write?extra_label=foo=bar would add {foo="bar"} label to all the ingested metrics.
Some plugins for Telegraf such as fluentd, Juniper/open-nti
or Juniper/jitmon send SHOW DATABASES query to /query and expect a particular database name in the response.
Comma-separated list of expected databases can be passed to VictoriaMetrics via -influx.databaseNames command-line flag.
How to send data in InfluxDB v2 format
VictoriaMetrics exposes endpoint for InfluxDB v2 HTTP API at /influx/api/v2/write and /api/v2/write.
In order to write data with InfluxDB line protocol to local VictoriaMetrics using curl:
curl -d 'measurement,tag1=value1,tag2=value2 field1=123,field2=1.23' -X POST 'http://localhost:8428/api/v2/write'
The /api/v1/export endpoint should return the following response:
{"metric":{"__name__":"measurement_field1","tag1":"value1","tag2":"value2"},"values":[123],"timestamps":[1695902762311]}
{"metric":{"__name__":"measurement_field2","tag1":"value1","tag2":"value2"},"values":[1.23],"timestamps":[1695902762311]}
How to send data from Graphite-compatible agents such as StatsD
Enable Graphite receiver in VictoriaMetrics by setting -graphiteListenAddr command line flag. For instance,
the following command will enable Graphite receiver in VictoriaMetrics on TCP and UDP port 2003:
/path/to/victoria-metrics-prod -graphiteListenAddr=:2003
Use the configured address in Graphite-compatible agents. For instance, set graphiteHost
to the VictoriaMetrics host in StatsD configs.
Example for writing data with Graphite plaintext protocol to local VictoriaMetrics using nc:
echo "foo.bar.baz;tag1=value1;tag2=value2 123 `date +%s`" | nc -N localhost 2003
The ingested metrics can be sanitized according to Prometheus naming convention by passing -graphite.sanitizeMetricName command-line flag
to VictoriaMetrics. The following modifications are applied to the ingested samples when this flag is passed to VictoriaMetrics:
- remove redundant dots, e.g:
metric..name=>metric.name - replace characters not matching
a-zA-Z0-9:_.chars with_
VictoriaMetrics sets the current time to the ingested samples if the timestamp is omitted.
An arbitrary number of lines delimited by \n (aka newline char) can be sent in one go.
After that the data may be read via /api/v1/export endpoint:
curl -G 'http://localhost:8428/api/v1/export' -d 'match=foo.bar.baz'
The /api/v1/export endpoint should return the following response:
{"metric":{"__name__":"foo.bar.baz","tag1":"value1","tag2":"value2"},"values":[123],"timestamps":[1560277406000]}
Graphite relabeling can be used if the imported Graphite data is going to be queried via MetricsQL.
Querying Graphite data
Data sent to VictoriaMetrics via Graphite plaintext protocol may be read via the following APIs:
Selecting Graphite metrics
VictoriaMetrics supports __graphite__ pseudo-label for selecting time series with Graphite-compatible filters in MetricsQL. For example, {__graphite__="foo.*.bar"} is equivalent to {__name__=~"foo[.][^.]*[.]bar"}, but it works faster and it is easier to use when migrating from Graphite to VictoriaMetrics. See docs for Graphite paths and wildcards. VictoriaMetrics also supports label_graphite_group function for extracting the given groups from Graphite metric name.
The __graphite__ pseudo-label supports e.g. alternate regexp filters such as (value1|...|valueN). They are transparently converted to {value1,...,valueN} syntax used in Graphite. This allows using multi-value template variables in Grafana inside __graphite__ pseudo-label. For example, Grafana expands {__graphite__=~"foo.($bar).baz"} into {__graphite__=~"foo.(x|y).baz"} if $bar template variable contains x and y values. In this case the query is automatically converted into {__graphite__=~"foo.{x,y}.baz"} before execution.
VictoriaMetrics also supports Graphite query language - see these docs.
How to send data from OpenTSDB-compatible agents
VictoriaMetrics supports telnet put protocol and HTTP /api/put requests for ingesting OpenTSDB data. The same protocol is used for ingesting data in KairosDB.
Sending data via telnet put protocol
Enable OpenTSDB receiver in VictoriaMetrics by setting -opentsdbListenAddr command line flag. For instance,
the following command enables OpenTSDB receiver in VictoriaMetrics on TCP and UDP port 4242:
/path/to/victoria-metrics-prod -opentsdbListenAddr=:4242
Send data to the given address from OpenTSDB-compatible agents.
Example for writing data with OpenTSDB protocol to local VictoriaMetrics using nc:
echo "put foo.bar.baz `date +%s` 123 tag1=value1 tag2=value2" | nc -N localhost 4242
An arbitrary number of lines delimited by \n (aka newline char) can be sent in one go.
After that the data may be read via /api/v1/export endpoint:
curl -G 'http://localhost:8428/api/v1/export' -d 'match=foo.bar.baz'
The /api/v1/export endpoint should return the following response:
{"metric":{"__name__":"foo.bar.baz","tag1":"value1","tag2":"value2"},"values":[123],"timestamps":[1560277292000]}
Sending OpenTSDB data via HTTP /api/put requests
Enable HTTP server for OpenTSDB /api/put requests by setting -opentsdbHTTPListenAddr command line flag. For instance,
the following command enables OpenTSDB HTTP server on port 4242:
/path/to/victoria-metrics-prod -opentsdbHTTPListenAddr=:4242
Send data to the given address from OpenTSDB-compatible agents.
Example for writing a single data point:
curl -H 'Content-Type: application/json' -d '{"metric":"x.y.z","value":45.34,"tags":{"t1":"v1","t2":"v2"}}' http://localhost:4242/api/put
Example for writing multiple data points in a single request:
curl -H 'Content-Type: application/json' -d '[{"metric":"foo","value":45.34},{"metric":"bar","value":43}]' http://localhost:4242/api/put
After that the data may be read via /api/v1/export endpoint:
curl -G 'http://localhost:8428/api/v1/export' -d 'match[]=x.y.z' -d 'match[]=foo' -d 'match[]=bar'
The /api/v1/export endpoint should return the following response:
{"metric":{"__name__":"foo"},"values":[45.34],"timestamps":[1566464846000]}
{"metric":{"__name__":"bar"},"values":[43],"timestamps":[1566464846000]}
{"metric":{"__name__":"x.y.z","t1":"v1","t2":"v2"},"values":[45.34],"timestamps":[1566464763000]}
Extra labels may be added to all the imported time series by passing extra_label=name=value query args.
For example, /api/put?extra_label=foo=bar would add {foo="bar"} label to all the ingested metrics.
How to send data from NewRelic agent
VictoriaMetrics accepts data from NewRelic infrastructure agent
at /newrelic/infra/v2/metrics/events/bulk HTTP path.
VictoriaMetrics receives Events
from NewRelic agent at the given path, transforms them to raw samples
according to these docs before storing the raw samples to the database.
You need passing COLLECTOR_URL and NRIA_LICENSE_KEY environment variables to NewRelic infrastructure agent in order to send the collected metrics to VictoriaMetrics.
The COLLECTOR_URL must point to /newrelic HTTP endpoint at VictoriaMetrics, while the NRIA_LICENSE_KEY must contain NewRelic license key,
which can be obtained here.
For example, if VictoriaMetrics runs at localhost:8428, then the following command can be used for running NewRelic infrastructure agent:
COLLECTOR_URL="http://localhost:8428/newrelic" NRIA_LICENSE_KEY="NEWRELIC_LICENSE_KEY" ./newrelic-infra
NewRelic agent data mapping
VictoriaMetrics maps NewRelic Events to raw samples in the following way:
- Every numeric field is converted into a raw sample with the corresponding name.
- The
eventTypeand all the other fields withstringvalue type are attached to every raw sample as metric labels. - The
timestampfield is used as timestamp for the ingested raw sample. Thetimestampfield may be specified either in seconds or in milliseconds since the Unix Epoch. If thetimestampfield is missing, then the raw sample is stored with the current timestamp.
For example, let's import the following NewRelic Events request to VictoriaMetrics:
[
{
"Events":[
{
"eventType":"SystemSample",
"entityKey":"macbook-pro.local",
"cpuPercent":25.056660790748904,
"cpuUserPercent":8.687987912389374,
"cpuSystemPercent":16.36867287835953,
"cpuIOWaitPercent":0,
"cpuIdlePercent":74.94333920925109,
"cpuStealPercent":0,
"loadAverageOneMinute":5.42333984375,
"loadAverageFiveMinute":4.099609375,
"loadAverageFifteenMinute":3.58203125
}
]
}
]
Save this JSON into newrelic.json file and then use the following command in order to import it into VictoriaMetrics:
curl -X POST -H 'Content-Type: application/json' --data-binary @newrelic.json http://localhost:8428/newrelic/infra/v2/metrics/events/bulk
Let's fetch the ingested data via data export API:
curl http://localhost:8428/api/v1/export -d 'match={eventType="SystemSample"}'
{"metric":{"__name__":"cpuStealPercent","entityKey":"macbook-pro.local","eventType":"SystemSample"},"values":[0],"timestamps":[1697407970000]}
{"metric":{"__name__":"loadAverageFiveMinute","entityKey":"macbook-pro.local","eventType":"SystemSample"},"values":[4.099609375],"timestamps":[1697407970000]}
{"metric":{"__name__":"cpuIOWaitPercent","entityKey":"macbook-pro.local","eventType":"SystemSample"},"values":[0],"timestamps":[1697407970000]}
{"metric":{"__name__":"cpuSystemPercent","entityKey":"macbook-pro.local","eventType":"SystemSample"},"values":[16.368672878359],"timestamps":[1697407970000]}
{"metric":{"__name__":"loadAverageOneMinute","entityKey":"macbook-pro.local","eventType":"SystemSample"},"values":[5.42333984375],"timestamps":[1697407970000]}
{"metric":{"__name__":"cpuUserPercent","entityKey":"macbook-pro.local","eventType":"SystemSample"},"values":[8.687987912389],"timestamps":[1697407970000]}
{"metric":{"__name__":"cpuIdlePercent","entityKey":"macbook-pro.local","eventType":"SystemSample"},"values":[74.9433392092],"timestamps":[1697407970000]}
{"metric":{"__name__":"loadAverageFifteenMinute","entityKey":"macbook-pro.local","eventType":"SystemSample"},"values":[3.58203125],"timestamps":[1697407970000]}
{"metric":{"__name__":"cpuPercent","entityKey":"macbook-pro.local","eventType":"SystemSample"},"values":[25.056660790748],"timestamps":[1697407970000]}
Prometheus querying API usage
VictoriaMetrics supports the following handlers from Prometheus querying API:
- /api/v1/query
- /api/v1/query_range
- /api/v1/series
- /api/v1/labels
- /api/v1/label/.../values
- /api/v1/status/tsdb. See these docs for details.
- /api/v1/targets - see these docs for more details.
- /federate - see these docs for more details.
These handlers can be queried from Prometheus-compatible clients such as Grafana or curl.
All the Prometheus querying API handlers can be prepended with /prometheus prefix. For example, both /prometheus/api/v1/query and /api/v1/query should work.
Prometheus querying API enhancements
VictoriaMetrics accepts optional extra_label=<label_name>=<label_value> query arg, which can be used
for enforcing additional label filters for queries. For example, /api/v1/query_range?extra_label=user_id=123&extra_label=group_id=456&query=<query>
would automatically add {user_id="123",group_id="456"} label filters to the given <query>.
This functionality can be used for limiting the scope of time series visible to the given tenant.
It is expected that the extra_label query args are automatically set by auth proxy sitting in front of VictoriaMetrics.
See vmauth and vmgateway as examples of such proxies.
VictoriaMetrics accepts optional extra_filters[]=series_selector query arg, which can be used for enforcing arbitrary label filters for queries.
For example, /api/v1/query_range?extra_filters[]={env=~"prod|staging",user="xyz"}&query=<query> would automatically
add {env=~"prod|staging",user="xyz"} label filters to the given <query>. This functionality can be used for limiting
the scope of time series visible to the given tenant. It is expected that the extra_filters[] query args are automatically
set by auth proxy sitting in front of VictoriaMetrics.
See vmauth and vmgateway as examples of such proxies.
VictoriaMetrics accepts multiple formats for time, start and end query args - see these docs.
VictoriaMetrics accepts round_digits query arg for /api/v1/query
and /api/v1/query_range handlers. It can be used for rounding response values
to the given number of digits after the decimal point.
For example, /api/v1/query?query=avg_over_time(temperature[1h])&round_digits=2 would round response values to up to two digits after the decimal point.
VictoriaMetrics accepts limit query arg for /api/v1/labels
and /api/v1/label/<labelName>/values handlers for limiting the number of returned entries.
For example, the query to /api/v1/labels?limit=5 returns a sample of up to 5 unique labels, while ignoring the rest of labels.
If the provided limit value exceeds the corresponding -search.maxTagKeys / -search.maxTagValues command-line flag values,
then limits specified in the command-line flags are used.
By default, VictoriaMetrics returns time series for the last day starting at 00:00 UTC
from /api/v1/series,
/api/v1/labels and
/api/v1/label/<labelName>/values,
while the Prometheus API defaults to all time. Explicitly set start and end to select the desired time range.
VictoriaMetrics rounds the specified start..end time range to day granularity because of performance optimization concerns.
If you need the exact set of label names and label values on the given time range, then send queries
to /api/v1/query or to /api/v1/query_range.
VictoriaMetrics accepts limit query arg at /api/v1/series
for limiting the number of returned entries. For example, the query to /api/v1/series?limit=5 returns a sample of up to 5 series, while ignoring the rest of series.
If the provided limit value exceeds the corresponding -search.maxSeries command-line flag values, then limits specified in the command-line flags are used.
VictoriaMetrics returns an extra object stats in JSON response for /api/v1/query
and /api/v1/query_range APIs. This object contains two
fields: executionTimeMsec with number of milliseconds the request took and seriesFetched with number of series that
were fetched from database before filtering. The seriesFetched field is effectively used by vmalert for detecting
misconfigured rule expressions. Please note, seriesFetched
provides approximate number of series, it is not recommended to rely on it in tests.
Additionally, VictoriaMetrics provides the following handlers:
-
/vmui- Basic Web UI. See these docs. -
/api/v1/series/count- returns the total number of time series in the database. Some notes:- the handler scans all the inverted index, so it can be slow if the database contains tens of millions of time series;
- the handler may count deleted time series additionally to normal time series due to internal implementation restrictions;
-
/api/v1/status/active_queries- returns the list of currently running queries. This list is also available atactive queriespage at VMUI. -
/api/v1/status/top_queries- returns the following query lists:- the most frequently executed queries -
topByCount - queries with the biggest average execution duration -
topByAvgDuration - queries that took the most time for execution -
topBySumDuration
The number of returned queries can be limited via
topNquery arg. Old queries can be filtered out withmaxLifetimequery arg. For example, request to/api/v1/status/top_queries?topN=5&maxLifetime=30swould return up to 5 queries per list, which were executed during the last 30 seconds. VictoriaMetrics tracks the last-search.queryStats.lastQueriesCountqueries with durations at least-search.queryStats.minQueryDuration.See also
top queriespage at VMUI. - the most frequently executed queries -
Timestamp formats
VictoriaMetrics accepts the following formats for time, start and end query args
in query APIs and
in export APIs.
- Unix timestamps in seconds with optional milliseconds after the point. For example,
1562529662.678. - Unix timestamps in milliseconds. For example,
1562529662678. - RFC3339. For example,
2022-03-29T01:02:03Zor2022-03-29T01:02:03+02:30. - Partial RFC3339. Examples:
2022,2022-03,2022-03-29,2022-03-29T01,2022-03-29T01:02,2022-03-29T01:02:03. The partial RFC3339 time is in local timezone of the host where VictoriaMetrics runs. It is possible to specify the needed timezone by addingZ(UTC),+hh:mmor-hh:mmsuffix to partial time. For example,2022-03-01Zcorresponds to the given date in UTC timezone, while2022-03-01+06:30corresponds to2022-03-01date at06:30timezone. - Relative duration comparing to the current time. For example,
1h5m,-1h5mornow-1h5mmeansone hour and five minutes ago, whilenowmeansnow.
Graphite API usage
VictoriaMetrics supports data ingestion in Graphite protocol - see these docs for details. VictoriaMetrics supports the following Graphite querying APIs, which are needed for Graphite datasource in Grafana:
- Render API - see these docs.
- Metrics API - see these docs.
- Tags API - see these docs.
All the Graphite handlers can be pre-pended with /graphite prefix. For example, both /graphite/metrics/find and /metrics/find should work.
VictoriaMetrics accepts optional query args: extra_label=<label_name>=<label_value> and extra_filters[]=series_selector query args for all the Graphite APIs. These args can be used for limiting the scope of time series visible to the given tenant. It is expected that the extra_label query arg is automatically set by auth proxy sitting in front of VictoriaMetrics. See vmauth and vmgateway as examples of such proxies.
Contact us if you need assistance with such a proxy.
VictoriaMetrics supports __graphite__ pseudo-label for filtering time series with Graphite-compatible filters in MetricsQL. See these docs.
Graphite Render API usage
VictoriaMetrics supports Graphite Render API subset
at /render endpoint, which is used by Graphite datasource in Grafana.
When configuring Graphite datasource in Grafana, the Storage-Step http request header must be set to a step between Graphite data points
stored in VictoriaMetrics. For example, Storage-Step: 10s would mean 10 seconds distance between Graphite datapoints stored in VictoriaMetrics.
Known Incompatibilities with graphite-web
-
Timestamp Shifting: VictoriaMetrics does not support shifting response timestamps outside the request time range as
graphite-webdoes. This limitation impacts chained functions with time modifiers, such astimeShift(summarize). For more details, refer to this issue. -
Non-deterministic series order: due to the distributed nature of metrics processing, functions within the
seriesListsfamily can produce non-deterministic results. To ensure consistent results, arguments for these functions must be wrapped with a sorting function. For instance, the functiondivideSeriesLists(series_list_1, series_list_2)should be modified todivideSeriesLists(sortByName(series_list_1), sortByName(series_list_2)). See this issue for details.The affected functions include:
aggregateSeriesListsdiffSeriesListsmultiplySeriesListsdivideSeriesLists
Graphite Metrics API usage
VictoriaMetrics supports the following handlers from Graphite Metrics API:
VictoriaMetrics accepts the following additional query args at /metrics/find and /metrics/expand:
label- for selecting arbitrary label values. By default,label=__name__, i.e. metric names are selected.delimiter- for using different delimiters in metric name hierarchy. For example,/metrics/find?delimiter=_&query=node_*would return all the metric name prefixes that start withnode_. By defaultdelimiter=..
Graphite Tags API usage
VictoriaMetrics supports the following handlers from Graphite Tags API:
- /tags/tagSeries
- /tags/tagMultiSeries
- /tags
- /tags/{tag_name}
- /tags/findSeries
- /tags/autoComplete/tags
- /tags/autoComplete/values
- /tags/delSeries
How to build from sources
We recommend using either binary releases or docker images instead of building VictoriaMetrics from sources. Building from sources is reasonable when developing additional features specific to your needs or when testing bugfixes.
Development build
- Install Go. The minimum supported version is Go 1.22.
- Run
make victoria-metricsfrom the root folder of the repository. It buildsvictoria-metricsbinary and puts it into thebinfolder.
Production build
- Install docker.
- Run
make victoria-metrics-prodfrom the root folder of the repository. It buildsvictoria-metrics-prodbinary and puts it into thebinfolder.
ARM build
ARM build may run on Raspberry Pi or on energy-efficient ARM servers.
Development ARM build
- Install Go. The minimum supported version is Go 1.22.
- Run
make victoria-metrics-linux-armormake victoria-metrics-linux-arm64from the root folder of the repository. It buildsvictoria-metrics-linux-armorvictoria-metrics-linux-arm64binary respectively and puts it into thebinfolder.
Production ARM build
- Install docker.
- Run
make victoria-metrics-linux-arm-prodormake victoria-metrics-linux-arm64-prodfrom the root folder of the repository. It buildsvictoria-metrics-linux-arm-prodorvictoria-metrics-linux-arm64-prodbinary respectively and puts it into thebinfolder.
Pure Go build (CGO_ENABLED=0)
Pure Go mode builds only Go code without cgo dependencies.
- Install Go. The minimum supported version is Go 1.22.
- Run
make victoria-metrics-purefrom the root folder of the repository. It buildsvictoria-metrics-purebinary and puts it into thebinfolder.
Building docker images
Run make package-victoria-metrics. It builds victoriametrics/victoria-metrics:<PKG_TAG> docker image locally.
<PKG_TAG> is auto-generated image tag, which depends on source code in the repository.
The <PKG_TAG> may be manually set via PKG_TAG=foobar make package-victoria-metrics.
The base docker image is alpine but it is possible to use any other base image
by setting it via <ROOT_IMAGE> environment variable.
For example, the following command builds the image on top of scratch image:
ROOT_IMAGE=scratch make package-victoria-metrics
Building VictoriaMetrics with Podman
VictoriaMetrics can be built with Podman in either rootful or rootless mode.
When building via rootful Podman, simply add DOCKER=podman to the relevant make commandline. To build
via rootless Podman, add DOCKER=podman DOCKER_RUN="podman run --userns=keep-id" to the make
commandline.
For example: make victoria-metrics-pure DOCKER=podman DOCKER_RUN="podman run --userns=keep-id"
Note that production builds are not supported via Podman because Podman does not support buildx.
Start with docker-compose
Docker-compose helps to spin up VictoriaMetrics, vmagent and Grafana with one command. More details may be found here.
Setting up service
Read instructions on how to set up VictoriaMetrics as a service for your OS.
How to work with snapshots
Send a request to http://<victoriametrics-addr>:8428/snapshot/create endpoint in order to create
an instant snapshot.
The page returns the following JSON response on successful creation of snapshot:
{"status":"ok","snapshot":"<snapshot-name>"}
Snapshots are created under <-storageDataPath>/snapshots directory, where <-storageDataPath>
is the corresponding command-line flag value. Snapshots can be archived to backup storage at any time
with vmbackup.
Snapshots consist of a mix of hard-links and soft-links to various files and directories inside -storageDataPath.
See this article
for more details. This adds some restrictions on what can be done with the contents of <-storageDataPath>/snapshots directory:
- Do not delete subdirectories inside
<-storageDataPath>/snapshotswithrmor similar commands, since this will leave some snapshot data undeleted. Prefer using the/snapshot/deleteAPI for deleting snapshot. See below for more details about this API. - Do not copy subdirectories inside
<-storageDataPath>/snapshotwithcp,rsyncor similar commands, since there are high chances that these commands won't copy some data stored in the snapshot. Prefer using vmbackup for making copies of snapshot data.
See also snapshot troubleshooting.
The http://<victoriametrics-addr>:8428/snapshot/list endpoint returns the list of available snapshots.
Send a query to http://<victoriametrics-addr>:8428/snapshot/delete?snapshot=<snapshot-name> in order
to delete the snapshot with <snapshot-name> name.
Navigate to http://<victoriametrics-addr>:8428/snapshot/delete_all in order to delete all the snapshots.
How to restore from a snapshot
- Stop VictoriaMetrics with
kill -INT. - Restore snapshot contents from backup with vmrestore
to the directory pointed by
-storageDataPath. - Start VictoriaMetrics.
Snapshot troubleshooting
Snapshot doesn't occupy disk space just after its' creation thanks to the used approach.
Old snapshots may start occupying additional disk space if they refer to old parts, which were already deleted during background merge.
That's why it is recommended deleting old snapshots after they are no longer needed in order to free up disk space used by old snapshots.
This can be done either manually or automatically if the -snapshotsMaxAge command-line flag is set. Make sure that the backup process has enough time to complete
when setting -snapshotsMaxAge command-line flag.
VictoriaMetrics exposes the current number of available snapshots via vm_snapshots metric at /metrics page.
How to delete time series
Send a request to http://<victoriametrics-addr>:8428/api/v1/admin/tsdb/delete_series?match[]=<timeseries_selector_for_delete>,
where <timeseries_selector_for_delete> may contain any time series selector
for metrics to delete. Delete API doesn't support the deletion of specific time ranges, the series can only be deleted completely.
Storage space for the deleted time series isn't freed instantly - it is freed during subsequent
background merges of data files.
Note that background merges may never occur for data from previous months, so storage space won't be freed for historical data. In this case forced merge may help freeing up storage space.
It is recommended verifying which metrics will be deleted with the call to http://<victoria-metrics-addr>:8428/api/v1/series?match[]=<timeseries_selector_for_delete>
before actually deleting the metrics. By default, this query will only scan series in the past 5 minutes, so you may need to
adjust start and end to a suitable range to achieve match hits. Also, if the
number of returned time series is rather big you will need to set
-search.maxDeleteSeries flag (see
Resource usage limits).
The /api/v1/admin/tsdb/delete_series handler may be protected with authKey if -deleteAuthKey command-line flag is set.
Note that handler accepts any HTTP method, so sending a GET request to /api/v1/admin/tsdb/delete_series will result in deletion of time series.
The delete API is intended mainly for the following cases:
- One-off deleting of accidentally written invalid (or undesired) time series.
- One-off deleting of user data due to GDPR.
Using the delete API is not recommended in the following cases, since it brings a non-zero overhead:
- Regular cleanups for unneeded data. Just prevent writing unneeded data into VictoriaMetrics. This can be done with relabeling. See this article for details.
- Reducing disk space usage by deleting unneeded time series. This doesn't work as expected, since the deleted time series occupy disk space until the next merge operation, which can never occur when deleting too old data. Forced merge may be used for freeing up disk space occupied by old data. Note that VictoriaMetrics doesn't delete entries from IndexDB for the deleted time series. IndexDB is cleaned up once per the configured retention.
It's better to use the -retentionPeriod command-line flag for efficient pruning of old data.
Forced merge
VictoriaMetrics performs data compactions in background
in order to keep good performance characteristics when accepting new data. These compactions (merges) are performed independently on per-month partitions.
This means that compactions are stopped for per-month partitions if no new data is ingested into these partitions.
Sometimes it is necessary to trigger compactions for old partitions. For instance, in order to free up disk space occupied by deleted time series.
In this case forced compaction may be initiated on the specified per-month partition by sending request to /internal/force_merge?partition_prefix=YYYY_MM,
where YYYY_MM is per-month partition name. For example, http://victoriametrics:8428/internal/force_merge?partition_prefix=2020_08 would initiate forced
merge for August 2020 partition. The call to /internal/force_merge returns immediately, while the corresponding forced merge continues running in background.
Forced merges may require additional CPU, disk IO and storage space resources. It is unnecessary to run forced merge under normal conditions, since VictoriaMetrics automatically performs optimal merges in background when new data is ingested into it.
How to export time series
VictoriaMetrics provides the following handlers for exporting data:
/api/v1/exportfor exporting data in JSON line format. See these docs for details./api/v1/export/csvfor exporting data in CSV. See these docs for details./api/v1/export/nativefor exporting data in native binary format. This is the most efficient format for data export. See these docs for details.
How to export data in JSON line format
Send a request to http://<victoriametrics-addr>:8428/api/v1/export?match[]=<timeseries_selector_for_export>,
where <timeseries_selector_for_export> may contain any time series selector
for metrics to export. Use {__name__!=""} selector for fetching all the time series.
The response would contain all the data for the selected time series in JSON line format - see these docs for details on this format.
Each JSON line contains samples for a single time series. An example output:
{"metric":{"__name__":"up","job":"node_exporter","instance":"localhost:9100"},"values":[0,0,0],"timestamps":[1549891472010,1549891487724,1549891503438]}
{"metric":{"__name__":"up","job":"prometheus","instance":"localhost:9090"},"values":[1,1,1],"timestamps":[1549891461511,1549891476511,1549891491511]}
Optional start and end args may be added to the request in order to limit the time frame for the exported data.
See allowed formats for these args.
For example:
curl http://<victoriametrics-addr>:8428/api/v1/export -d 'match[]=<timeseries_selector_for_export>' -d 'start=1654543486' -d 'end=1654543486'
curl http://<victoriametrics-addr>:8428/api/v1/export -d 'match[]=<timeseries_selector_for_export>' -d 'start=2022-06-06T19:25:48' -d 'end=2022-06-06T19:29:07'
Optional max_rows_per_line arg may be added to the request for limiting the maximum number of rows exported per each JSON line.
Optional reduce_mem_usage=1 arg may be added to the request for reducing memory usage when exporting big number of time series.
In this case the output may contain multiple lines with samples for the same time series.
Pass Accept-Encoding: gzip HTTP header in the request to /api/v1/export in order to reduce network bandwidth during exporting big amounts
of time series data. This enables gzip compression for the exported data. Example for exporting gzipped data:
curl -H 'Accept-Encoding: gzip' http://localhost:8428/api/v1/export -d 'match[]={__name__!=""}' > data.jsonl.gz
The maximum duration for each request to /api/v1/export is limited by -search.maxExportDuration command-line flag.
Exported data can be imported via POST'ing it to /api/v1/import.
The deduplication is applied to the data exported via /api/v1/export by default. The deduplication
isn't applied if reduce_mem_usage=1 query arg is passed to the request.
How to export CSV data
Send a request to http://<victoriametrics-addr>:8428/api/v1/export/csv?format=<format>&match=<timeseries_selector_for_export>,
where:
-
<format>must contain comma-delimited label names for the exported CSV. The following special label names are supported:__name__- metric name__value__- sample value__timestamp__:<ts_format>- sample timestamp.<ts_format>can have the following values:unix_s- unix secondsunix_ms- unix millisecondsunix_ns- unix nanosecondsrfc3339- RFC3339 time (in the timezone of the server)custom:<layout>- custom layout for time that is supported by time.Format function from Go.
-
<timeseries_selector_for_export>may contain any time series selector for metrics to export.
Optional start and end args may be added to the request in order to limit the time frame for the exported data.
See allowed formats for these args.
For example:
curl http://<victoriametrics-addr>:8428/api/v1/export/csv -d 'format=<format>' -d 'match[]=<timeseries_selector_for_export>' -d 'start=1654543486' -d 'end=1654543486'
curl http://<victoriametrics-addr>:8428/api/v1/export/csv -d 'format=<format>' -d 'match[]=<timeseries_selector_for_export>' -d 'start=2022-06-06T19:25:48' -d 'end=2022-06-06T19:29:07'
The exported CSV data can be imported to VictoriaMetrics via /api/v1/import/csv.
The deduplication is applied for the data exported in CSV by default. It is possible to export raw data without de-duplication by passing reduce_mem_usage=1 query arg to /api/v1/export/csv.
How to export data in native format
Send a request to http://<victoriametrics-addr>:8428/api/v1/export/native?match[]=<timeseries_selector_for_export>,
where <timeseries_selector_for_export> may contain any time series selector
for metrics to export. Use {__name__=~".*"} selector for fetching all the time series.
On large databases you may experience problems with limit on the number of time series, which can be exported. In this case you need to adjust -search.maxExportSeries command-line flag:
# count unique time series in database
wget -O- -q 'http://your_victoriametrics_instance:8428/api/v1/series/count' | jq '.data[0]'
# relaunch victoriametrics with search.maxExportSeries more than value from previous command
Optional start and end args may be added to the request in order to limit the time frame for the exported data.
See allowed formats for these args.
For example:
curl http://<victoriametrics-addr>:8428/api/v1/export/native -d 'match[]=<timeseries_selector_for_export>' -d 'start=1654543486' -d 'end=1654543486'
curl http://<victoriametrics-addr>:8428/api/v1/export/native -d 'match[]=<timeseries_selector_for_export>' -d 'start=2022-06-06T19:25:48' -d 'end=2022-06-06T19:29:07'
The exported data can be imported to VictoriaMetrics via /api/v1/import/native. The native export format may change in incompatible way between VictoriaMetrics releases, so the data exported from the release X can fail to be imported into VictoriaMetrics release Y.
The deduplication isn't applied for the data exported in native format. It is expected that the de-duplication is performed during data import.
How to import time series data
VictoriaMetrics can discover and scrape metrics from Prometheus-compatible targets (aka "pull" protocol) - see these docs. Additionally, VictoriaMetrics can accept metrics via the following popular data ingestion protocols (aka "push" protocols):
- Prometheus remote_write API. See these docs for details.
- DataDog
submit metricsAPI. See these docs for details. - InfluxDB line protocol. See these docs for details.
- Graphite plaintext protocol. See these docs for details.
- OpenTelemetry http API. See these docs for details.
- OpenTSDB telnet put protocol. See these docs for details.
- OpenTSDB http
/api/putprotocol. See these docs for details. /api/v1/importfor importing data obtained from /api/v1/export. See these docs for details./api/v1/import/nativefor importing data obtained from /api/v1/export/native. See these docs for details./api/v1/import/csvfor importing arbitrary CSV data. See these docs for details./api/v1/import/prometheusfor importing data in Prometheus exposition format and in Pushgateway format. See these docs for details.
Please note, most of the ingestion APIs (except Prometheus remote_write API, OpenTelemetry and Influx Line Protocol)
are optimized for performance and processes data in a streaming fashion.
It means that client can transfer unlimited amount of data through the open connection. Because of this, import APIs
may not return parsing errors to the client, as it is expected for data stream to be not interrupted.
Instead, look for parsing errors on the server side (VictoriaMetrics single-node or vminsert) or
check for changes in vm_rows_invalid_total (exported by server side) metric.
How to import data in JSON line format
VictoriaMetrics accepts metrics data in JSON line format at /api/v1/import endpoint. See these docs for details on this format.
Example for importing data obtained via /api/v1/export:
# Export the data from <source-victoriametrics>:
curl http://source-victoriametrics:8428/api/v1/export -d 'match={__name__!=""}' > exported_data.jsonl
# Import the data to <destination-victoriametrics>:
curl -X POST http://destination-victoriametrics:8428/api/v1/import -T exported_data.jsonl
Pass Content-Encoding: gzip HTTP request header to /api/v1/import for importing gzipped data:
# Export gzipped data from <source-victoriametrics>:
curl -H 'Accept-Encoding: gzip' http://source-victoriametrics:8428/api/v1/export -d 'match={__name__!=""}' > exported_data.jsonl.gz
# Import gzipped data to <destination-victoriametrics>:
curl -X POST -H 'Content-Encoding: gzip' http://destination-victoriametrics:8428/api/v1/import -T exported_data.jsonl.gz
Extra labels may be added to all the imported time series by passing extra_label=name=value query args.
For example, /api/v1/import?extra_label=foo=bar would add "foo":"bar" label to all the imported time series.
Note that it could be required to flush response cache after importing historical data. See these docs for detail.
VictoriaMetrics parses input JSON lines one-by-one. It loads the whole JSON line in memory, then parses it and then saves the parsed samples into persistent storage.
This means that VictoriaMetrics can occupy big amounts of RAM when importing too long JSON lines.
The solution is to split too long JSON lines into shorter lines. It is OK if samples for a single time series are split among multiple JSON lines.
JSON line length can be limited via max_rows_per_line query arg when exporting via /api/v1/export.
The maximum JSON line length, which can be parsed by VictoriaMetrics, is limited by -import.maxLineLen command-line flag value.
How to import data in native format
The specification of VictoriaMetrics' native format may yet change and is not formally documented yet. So currently we do not recommend that external clients attempt to pack their own metrics in native format file.
If you have a native format file obtained via /api/v1/export/native however this is the most efficient protocol for importing data in.
# Export the data from <source-victoriametrics>:
curl http://source-victoriametrics:8428/api/v1/export/native -d 'match={__name__!=""}' > exported_data.bin
# Import the data to <destination-victoriametrics>:
curl -X POST http://destination-victoriametrics:8428/api/v1/import/native -T exported_data.bin
Extra labels may be added to all the imported time series by passing extra_label=name=value query args.
For example, /api/v1/import/native?extra_label=foo=bar would add "foo":"bar" label to all the imported time series.
Note that it could be required to flush response cache after importing historical data. See these docs for detail.
How to import CSV data
Arbitrary CSV data can be imported via /api/v1/import/csv. The CSV data is imported according to the provided format query arg.
The format query arg must contain comma-separated list of parsing rules for CSV fields. Each rule consists of three parts delimited by a colon:
<column_pos>:<type>:<context>
<column_pos>is the position of the CSV column (field). Column numbering starts from 1. The order of parsing rules may be arbitrary.<type>describes the column type. Supported types are:metric- the corresponding CSV column at<column_pos>contains metric value, which must be integer or floating-point number. The metric name is read from the<context>. CSV line must have at least a single metric field. Multiple metric fields per CSV line is OK.label- the corresponding CSV column at<column_pos>contains label value. The label name is read from the<context>. CSV line may have arbitrary number of label fields. All these labels are attached to all the configured metrics.time- the corresponding CSV column at<column_pos>contains metric time. CSV line may contain either one or zero columns with time. If CSV line has no time, then the current time is used. The time is applied to all the configured metrics. The format of the time is configured via<context>. Supported time formats are:unix_s- unix timestamp in seconds.unix_ms- unix timestamp in milliseconds.unix_ns- unix timestamp in nanoseconds. Note that VictoriaMetrics rounds the timestamp to milliseconds.rfc3339- timestamp in RFC3339 format, i.e.2006-01-02T15:04:05Z.custom:<layout>- custom layout for the timestamp. The<layout>may contain arbitrary time layout according to time.Parse rules in Go.
Each request to /api/v1/import/csv may contain arbitrary number of CSV lines.
Example for importing CSV data via /api/v1/import/csv:
curl -d "GOOG,1.23,4.56,NYSE" 'http://localhost:8428/api/v1/import/csv?format=2:metric:ask,3:metric:bid,1:label:ticker,4:label:market'
curl -d "MSFT,3.21,1.67,NASDAQ" 'http://localhost:8428/api/v1/import/csv?format=2:metric:ask,3:metric:bid,1:label:ticker,4:label:market'
After that the data may be read via /api/v1/export endpoint:
curl -G 'http://localhost:8428/api/v1/export' -d 'match[]={ticker!=""}'
The following response should be returned:
{"metric":{"__name__":"bid","market":"NASDAQ","ticker":"MSFT"},"values":[1.67],"timestamps":[1583865146520]}
{"metric":{"__name__":"bid","market":"NYSE","ticker":"GOOG"},"values":[4.56],"timestamps":[1583865146495]}
{"metric":{"__name__":"ask","market":"NASDAQ","ticker":"MSFT"},"values":[3.21],"timestamps":[1583865146520]}
{"metric":{"__name__":"ask","market":"NYSE","ticker":"GOOG"},"values":[1.23],"timestamps":[1583865146495]}
Extra labels may be added to all the imported lines by passing extra_label=name=value query args.
For example, /api/v1/import/csv?extra_label=foo=bar would add "foo":"bar" label to all the imported lines.
Note that it could be required to flush response cache after importing historical data. See these docs for detail.
How to import data in Prometheus exposition format
VictoriaMetrics accepts data in Prometheus exposition format,
in OpenMetrics format
and in Pushgateway format via /api/v1/import/prometheus path.
For example, the following command imports a single line in Prometheus exposition format into VictoriaMetrics:
curl -d 'foo{bar="baz"} 123' -X POST 'http://localhost:8428/api/v1/import/prometheus'
The following command may be used for verifying the imported data:
curl -G 'http://localhost:8428/api/v1/export' -d 'match={__name__=~"foo"}'
It should return something like the following:
{"metric":{"__name__":"foo","bar":"baz"},"values":[123],"timestamps":[1594370496905]}
The following command imports a single metric via Pushgateway format with {job="my_app",instance="host123"} labels:
curl -d 'metric{label="abc"} 123' -X POST 'http://localhost:8428/api/v1/import/prometheus/metrics/job/my_app/instance/host123'
Pass Content-Encoding: gzip HTTP request header to /api/v1/import/prometheus for importing gzipped data:
# Import gzipped data to <destination-victoriametrics>:
curl -X POST -H 'Content-Encoding: gzip' http://destination-victoriametrics:8428/api/v1/import/prometheus -T prometheus_data.gz
Extra labels may be added to all the imported metrics either via Pushgateway format
or by passing extra_label=name=value query args. For example, /api/v1/import/prometheus?extra_label=foo=bar would add {foo="bar"} label to all the imported metrics.
If timestamp is missing in <metric> <value> <timestamp> Prometheus exposition format line, then the current timestamp is used during data ingestion.
It can be overridden by passing unix timestamp in milliseconds via timestamp query arg. For example, /api/v1/import/prometheus?timestamp=1594370496905.
VictoriaMetrics accepts arbitrary number of lines in a single request to /api/v1/import/prometheus, i.e. it supports data streaming.
Note that it could be required to flush response cache after importing historical data. See these docs for detail.
VictoriaMetrics also may scrape Prometheus targets - see these docs.
Sending data via OpenTelemetry
VictoriaMetrics supports data ingestion via OpenTelemetry protocol for metrics at /opentelemetry/v1/metrics path.
VictoriaMetrics expects protobuf-encoded requests at /opentelemetry/v1/metrics.
Set HTTP request header Content-Encoding: gzip when sending gzip-compressed data to /opentelemetry/v1/metrics.
VictoriaMetrics supports only cumulative temporality
for received measurements. The number of dropped unsupported samples is exposed via vm_protoparser_rows_dropped_total{type="opentelemetry" metric.
VictoriaMetrics stores the ingested OpenTelemetry raw samples as is without any transformations.
Pass -opentelemetry.usePrometheusNaming command-line flag to VictoriaMetrics for automatic conversion of metric names and labels into Prometheus-compatible format.
OpenTelemetry exponential histogram is automatically converted
to VictoriaMetrics histogram format.
Using the following exporter configuration in the OpenTelemetry collector will allow you to send metrics into VictoriaMetrics:
exporters:
otlphttp/victoriametrics:
compression: gzip
encoding: proto
endpoint: http://<collector/vmagent>.<namespace>.svc.cluster.local:<port>/opentelemetry
Remember to add the exporter to the desired service pipeline in order to activate the exporter.
service:
pipelines:
metrics:
exporters:
- otlphttp/victoriametrics
receivers:
- otlp
See How to use OpenTelemetry metrics with VictoriaMetrics.
JSON line format
VictoriaMetrics accepts data in JSON line format at /api/v1/import and exports data in this format at /api/v1/export.
The format follows JSON streaming concept, e.g. each line contains JSON object with metrics data in the following format:
{
// metric contains metric name plus labels for a particular time series
"metric":{
"__name__": "metric_name", // <- this is metric name
// Other labels for the time series
"label1": "value1",
"label2": "value2",
...
"labelN": "valueN"
},
// values contains raw sample values for the given time series
"values": [1, 2.345, -678],
// timestamps contains raw sample UNIX timestamps in milliseconds for the given time series
// every timestamp is associated with the value at the corresponding position
"timestamps": [1549891472010,1549891487724,1549891503438]
}
Note that every JSON object must be written in a single line, e.g. all the newline chars must be removed from it.
/api/v1/import handler doesn't accept JSON lines longer than the value
passed to -import.maxLineLen command-line flag (by default this is 10MB).
It is recommended passing 1K-10K samples per line for achieving the maximum data ingestion performance at /api/v1/import. Too long JSON lines may increase RAM usage at VictoriaMetrics side.
/api/v1/export handler accepts max_rows_per_line query arg, which allows limiting the number of samples per each exported line.
It is OK to split raw samples for the same time series across multiple lines.
The number of lines in the request to /api/v1/import can be arbitrary - they are imported in streaming manner.
Relabeling
VictoriaMetrics supports Prometheus-compatible relabeling for all the ingested metrics if -relabelConfig command-line flag points
to a file containing a list of relabel_config entries.
The -relabelConfig also can point to http or https url. For example, -relabelConfig=https://config-server/relabel_config.yml.
The following docs can be useful in understanding the relabeling:
The -relabelConfig files can contain special placeholders in the form %{ENV_VAR}, which are replaced by the corresponding environment variable values.
Example contents for -relabelConfig file:
# Add {cluster="dev"} label.
- target_label: cluster
replacement: dev
# Drop the metric (or scrape target) with `{__meta_kubernetes_pod_container_init="true"}` label.
- action: drop
source_labels: [__meta_kubernetes_pod_container_init]
regex: true
VictoriaMetrics provides additional relabeling features such as Graphite-style relabeling. See these docs for more details.
The relabeling can be debugged at http://victoriametrics:8428/metric-relabel-debug page
or at our public playground.
See these docs for more details.
Federation
VictoriaMetrics exports Prometheus-compatible federation data
at http://<victoriametrics-addr>:8428/federate?match[]=<timeseries_selector_for_federation>.
Optional start and end args may be added to the request in order to scrape the last point for each selected time series on the [start ... end] interval.
See allowed formats for these args.
For example:
curl http://<victoriametrics-addr>:8428/federate -d 'match[]=<timeseries_selector_for_export>' -d 'start=1654543486' -d 'end=1654543486'
curl http://<victoriametrics-addr>:8428/federate -d 'match[]=<timeseries_selector_for_export>' -d 'start=2022-06-06T19:25:48' -d 'end=2022-06-06T19:29:07'
By default, the last point on the interval [now - max_lookback ... now] is scraped for each time series. The default value for max_lookback is 5m (5 minutes), but it can be overridden with max_lookback query arg.
For instance, /federate?match[]=up&max_lookback=1h would return last points on the [now - 1h ... now] interval. This may be useful for time series federation
with scrape intervals exceeding 5m.
Capacity planning
VictoriaMetrics uses lower amounts of CPU, RAM and storage space on production workloads compared to competing solutions (Prometheus, Thanos, Cortex, TimescaleDB, InfluxDB, QuestDB, M3DB) according to our case studies.
VictoriaMetrics capacity scales linearly with the available resources. The needed amounts of CPU and RAM highly depends on the workload - the number of active time series, series churn rate, query types, query qps, etc. It is recommended setting up a test VictoriaMetrics for your production workload and iteratively scaling CPU and RAM resources until it becomes stable according to troubleshooting docs. A single-node VictoriaMetrics works perfectly with the following production workload according to our case studies:
- Ingestion rate: 1.5+ million samples per second
- Active time series: 50+ million
- Total time series: 5+ billion
- Time series churn rate: 150+ million of new series per day
- Total number of samples: 10+ trillion
- Queries: 200+ qps
- Query latency (99th percentile): 1 second
The needed storage space for the given retention (the retention is set via -retentionPeriod command-line flag) can be extrapolated from disk space usage in a test run. For example, if -storageDataPath directory size becomes 10GB after a day-long test run on a production workload, then it will need at least 10GB*100=1TB of disk space for -retentionPeriod=100d (100-days retention period).
It is recommended leaving the following amounts of spare resources:
- 50% of free RAM for reducing the probability of OOM (out of memory) crashes and slowdowns during temporary spikes in workload.
- 50% of spare CPU for reducing the probability of slowdowns during temporary spikes in workload.
- At least 20% of free storage space at the directory pointed by
-storageDataPathcommand-line flag. See also-storage.minFreeDiskSpaceBytescommand-line flag description here.
See also resource usage limits docs.
Resource usage limits
By default, VictoriaMetrics is tuned for an optimal resource usage under typical workloads. Some workloads may need fine-grained resource usage limits. In these cases the following command-line flags may be useful:
-memory.allowedPercentand-memory.allowedByteslimit the amounts of memory, which may be used for various internal caches at VictoriaMetrics. Note that VictoriaMetrics may use more memory, since these flags don't limit additional memory, which may be needed on a per-query basis.-search.maxMemoryPerQuerylimits the amounts of memory, which can be used for processing a single query. Queries, which need more memory, are rejected. Heavy queries, which select big number of time series, may exceed the per-query memory limit by a small percent. The total memory limit for concurrently executed queries can be estimated as-search.maxMemoryPerQuerymultiplied by-search.maxConcurrentRequests.-search.maxUniqueTimeserieslimits the number of unique time series a single query can find and process. By default, VictoriaMetrics calculates the limit automatically based on the available memory and the maximum number of concurrent requests it can process (see-search.maxConcurrentRequests). VictoriaMetrics keeps in memory some metainformation about the time series located by each query and spends some CPU time for processing the found time series. This means that the maximum memory usage and CPU usage a single query can use is proportional to-search.maxUniqueTimeseries.-search.maxQueryDurationlimits the duration of a single query. If the query takes longer than the given duration, then it is canceled. This allows saving CPU and RAM when executing unexpected heavy queries. The limit can be overridden to a smaller value by passingtimeoutGET parameter.-search.maxConcurrentRequestslimits the number of concurrent requests VictoriaMetrics can process. Bigger number of concurrent requests usually means bigger memory usage. For example, if a single query needs 100 MiB of additional memory during its execution, then 100 concurrent queries may need100 * 100 MiB = 10 GiBof additional memory. So it is better to limit the number of concurrent queries, while pausing additional incoming queries if the concurrency limit is reached. VictoriaMetrics provides-search.maxQueueDurationcommand-line flag for limiting the max wait time for paused queries. See also-search.maxMemoryPerQuerycommand-line flag.-search.maxQueueDurationlimits the maximum duration queries may wait for execution when-search.maxConcurrentRequestsconcurrent queries are executed.-search.ignoreExtraFiltersAtLabelsAPIenables ignoring ofmatch[],extra_filters[]andextra_labelquery args at /api/v1/labels and /api/v1/label/.../values. This may be useful for reducing the load on VictoriaMetrics if the provided extra filters match too many time series. The downside is that the endpoints can return labels and series, which do not match the provided extra filters.-search.maxSamplesPerSerieslimits the number of raw samples the query can process per each time series. VictoriaMetrics sequentially processes raw samples per each found time series during the query. It unpacks raw samples on the selected time range per each time series into memory and then applies the given rollup function. The-search.maxSamplesPerSeriescommand-line flag allows limiting memory usage in the case when the query is executed on a time range, which contains hundreds of millions of raw samples per each located time series.-search.maxSamplesPerQuerylimits the number of raw samples a single query can process. This allows limiting CPU usage for heavy queries.-search.maxResponseSerieslimits the number of time series a single query can return from/api/v1/queryand/api/v1/query_range.-search.maxPointsPerTimeserieslimits the number of calculated points, which can be returned per each matching time series from range query.-search.maxPointsSubqueryPerTimeserieslimits the number of calculated points, which can be generated per each matching time series during subquery evaluation.-search.maxSeriesPerAggrFunclimits the number of time series, which can be generated by MetricsQL aggregate functions in a single query.-search.maxSerieslimits the number of time series, which may be returned from /api/v1/series. This endpoint is used mostly by Grafana for auto-completion of metric names, label names and label values. Queries to this endpoint may take big amounts of CPU time and memory when the database contains big number of unique time series because of high churn rate. In this case it might be useful to set the-search.maxSeriesto quite low value in order limit CPU and memory usage. See also-search.maxLabelsAPIDurationand-search.maxLabelsAPISeries.-search.maxDeleteSerieslimits the number of unique time series that can be deleted by a single /api/v1/admin/tsdb/delete_series call. Deleting too many time series may require big amount of CPU and memory and this limit guards against unplanned resource usage spikes. Also see How to delete time series section to learn about different ways of deleting series.-search.maxTagKeyslimits the number of items, which may be returned from /api/v1/labels. This endpoint is used mostly by Grafana for auto-completion of label names. Queries to this endpoint may take big amounts of CPU time and memory when the database contains big number of unique time series because of high churn rate. In this case it might be useful to set the-search.maxTagKeysto quite low value in order to limit CPU and memory usage. See also-search.maxLabelsAPIDurationand-search.maxLabelsAPISeries.-search.maxTagValueslimits the number of items, which may be returned from /api/v1/label/.../values. This endpoint is used mostly by Grafana for auto-completion of label values. Queries to this endpoint may take big amounts of CPU time and memory when the database contains big number of unique time series because of high churn rate. In this case it might be useful to set the-search.maxTagValuesto quite low value in order to limit CPU and memory usage. See also-search.maxLabelsAPIDurationand-search.maxLabelsAPISeries.-search.maxLabelsAPISerieslimits the number of time series, which can be scanned when performing /api/v1/labels, /api/v1/label/.../values or /api/v1/series requests. These endpoints are used mostly by Grafana for auto-completion of label names and label values. Queries to these endpoints may take big amounts of CPU time and memory when the database contains big number of unique time series because of high churn rate. In this case it might be useful to set the-search.maxLabelsAPISeriesto quite low value in order to limit CPU and memory usage. See also-search.maxLabelsAPIDurationand-search.ignoreExtraFiltersAtLabelsAPI.-search.maxLabelsAPIDurationlimits the duration for requests to /api/v1/labels, /api/v1/label/.../values or /api/v1/series. The limit can be overridden to a smaller value by passingtimeoutGET parameter. These endpoints are used mostly by Grafana for auto-completion of label names and label values. Queries to these endpoints may take big amounts of CPU time and memory when the database contains big number of unique time series because of high churn rate. In this case it might be useful to set the-search.maxLabelsAPIDurationto quite low value in order to limit CPU and memory usage. See also-search.maxLabelsAPISeriesand-search.ignoreExtraFiltersAtLabelsAPI.-search.maxTagValueSuffixesPerSearchlimits the number of entries, which may be returned from/metrics/findendpoint. See Graphite Metrics API usage docs.
See also resource usage limits at VictoriaMetrics cluster, cardinality limiter and capacity planning docs.
High availability
The general approach for achieving high availability is the following:
- To run two identically configured VictoriaMetrics instances in distinct datacenters (availability zones);
- To store the collected data simultaneously into these instances via vmagent or Prometheus.
- To query the first VictoriaMetrics instance and to fail over to the second instance when the first instance becomes temporarily unavailable. This can be done via vmauth according to these docs.
Such a setup guarantees that the collected data isn't lost when one of VictoriaMetrics instance becomes unavailable. The collected data continues to be written to the available VictoriaMetrics instance, so it should be available for querying. Both vmagent and Prometheus buffer the collected data locally if they cannot send it to the configured remote storage. So the collected data will be written to the temporarily unavailable VictoriaMetrics instance after it becomes available.
If you use vmagent for storing the data into VictoriaMetrics,
then it can be configured with multiple -remoteWrite.url command-line flags, where every flag points to the VictoriaMetrics
instance in a particular availability zone, in order to replicate the collected data to all the VictoriaMetrics instances.
For example, the following command instructs vmagent to replicate data to vm-az1 and vm-az2 instances of VictoriaMetrics:
/path/to/vmagent \
-remoteWrite.url=http://<vm-az1>:8428/api/v1/write \
-remoteWrite.url=http://<vm-az2>:8428/api/v1/write
If you use Prometheus for collecting and writing the data to VictoriaMetrics,
then the following remote_write section
in Prometheus config can be used for replicating the collected data to vm-az1 and vm-az2 VictoriaMetrics instances:
remote_write:
- url: http://<vm-az1>:8428/api/v1/write
- url: http://<vm-az2>:8428/api/v1/write
It is recommended to use vmagent instead of Prometheus for highly loaded setups, since it uses lower amounts of RAM, CPU and network bandwidth than Prometheus.
If you use identically configured vmagent instances for collecting the same data and sending it to VictoriaMetrics, then do not forget enabling deduplication at VictoriaMetrics side.
Deduplication
VictoriaMetrics leaves a single raw sample
with the biggest timestamp for each time series
per each -dedup.minScrapeInterval discrete interval if -dedup.minScrapeInterval is set to positive duration.
For example, -dedup.minScrapeInterval=60s would leave a single raw sample with the biggest timestamp per each discrete
60s interval.
This aligns with the staleness rules in Prometheus.
If multiple raw samples have the same timestamp on the given -dedup.minScrapeInterval discrete interval,
then the sample with the biggest value is kept.
Prometheus staleness markers are processed as any other value during de-duplication.
If raw sample with the biggest timestamp on -dedup.minScrapeInterval contains a stale marker, then it is kept after the deduplication.
This allows properly preserving staleness markers during the de-duplication.
Please note, labels of raw samples should be identical in order to be deduplicated. For example, this is why HA pair of vmagents needs to be identically configured.
The -dedup.minScrapeInterval=D is equivalent to -downsampling.period=0s:D if downsampling is enabled.
So it is safe to use deduplication and downsampling simultaneously.
The recommended value for -dedup.minScrapeInterval must equal to scrape_interval config from Prometheus configs.
It is recommended to have a single scrape_interval across all the scrape targets.
See this article for details.
The de-duplication reduces disk space usage if multiple identically configured vmagent
or Prometheus instances in HA pair write data to the same VictoriaMetrics instance.
These vmagent or Prometheus instances must have identical external_labels section in their configs,
so they write data to the same time series.
See also how to set up multiple vmagent instances for scraping the same targets.
It is recommended passing different -promscrape.cluster.name values to each distinct HA pair of vmagent instances,
so the de-duplication consistently leaves samples for one vmagent instance and removes duplicate samples
from other vmagent instances.
See these docs for details.
VictoriaMetrics stores all the ingested samples to disk even if -dedup.minScrapeInterval command-line flag is set.
The ingested samples are de-duplicated during background merges and during query execution.
VictoriaMetrics also supports de-duplication during data ingestion before the data is stored to disk, via -streamAggr.dedupInterval command-line flag -
see these docs.
Storage
VictoriaMetrics buffers the ingested data in memory for up to a second. Then the buffered data is written to in-memory parts,
which can be searched during queries. The in-memory parts are periodically persisted to disk, so they could survive unclean shutdown
such as out of memory crash, hardware power loss or SIGKILL signal. The interval for flushing the in-memory data to disk
can be configured with the -inmemoryDataFlushInterval command-line flag (note that too short flush interval may significantly increase disk IO).
In-memory parts are persisted to disk into part directories under the <-storageDataPath>/data/small/YYYY_MM/ folder,
where YYYY_MM is the month partition for the stored data. For example, 2022_11 is the partition for parts
with raw samples from November 2022.
Each partition directory contains parts.json file with the actual list of parts in the partition.
Every part directory contains metadata.json file with the following fields:
RowsCount- the number of raw samples stored in the partBlocksCount- the number of blocks stored in the part (see details about blocks below)MinTimestampandMaxTimestamp- minimum and maximum timestamps across raw samples stored in the partMinDedupInterval- the deduplication interval applied to the given part.
Each part consists of blocks sorted by internal time series id (aka TSID).
Each block contains up to 8K raw samples,
which belong to a single time series.
Raw samples in each block are sorted by timestamp. Blocks for the same time series are sorted
by the timestamp of the first sample. Timestamps and values for all the blocks
are stored in compressed form
in separate files under part directory - timestamps.bin and values.bin.
The part directory also contains index.bin and metaindex.bin files - these files contain index
for fast block lookups, which belong to the given TSID and cover the given time range.
Parts are periodically merged into bigger parts in background. The background merge provides the following benefits:
- keeping the number of data files under control, so they don't exceed limits on open files
- improved data compression, since bigger parts are usually compressed better than smaller parts
- improved query speed, since queries over smaller number of parts are executed faster
- various background maintenance tasks such as de-duplication, downsampling and freeing up disk space for the deleted time series are performed during the merge
Newly added parts either successfully appear in the storage or fail to appear.
The newly added part is atomically registered in the parts.json file under the corresponding partition
after it is fully written and fsynced to the storage.
Thanks to this algorithm, storage never contains partially created parts, even if hardware power off
occurs in the middle of writing the part to disk - such incompletely written parts
are automatically deleted on the next VictoriaMetrics start.
The same applies to merge process — parts are either fully merged into a new part or fail to merge,
leaving the source parts untouched. However, due to hardware issues data on disk may be corrupted regardless of
VictoriaMetrics process. VictoriaMetrics can detect corruption during decompressing, decoding or sanity checking
of the data blocks. But it cannot fix the corrupted data. Data parts that fail to load on startup need to be deleted
or restored from backups. This is why it is recommended performing
regular backups.
VictoriaMetrics doesn't use checksums for stored data blocks. See why here.
VictoriaMetrics doesn't merge parts if their summary size exceeds free disk space.
This prevents from potential out of disk space errors during merge.
The number of parts may significantly increase over time under free disk space shortage.
This increases overhead during data querying, since VictoriaMetrics needs to read data from
bigger number of parts per each request. That's why it is recommended to have at least 20%
of free disk space under directory pointed by -storageDataPath command-line flag.
Information about merging process is available in the dashboard for single-node VictoriaMetrics and the dashboard for VictoriaMetrics cluster. See more details in monitoring docs.
See this article for more details.
See also how to work with snapshots and IndexDB.
IndexDB
VictoriaMetrics identifies
time series by
TSID (time series ID) and stores
raw samples sorted
by TSID (see Storage). Thus, the TSID is a primary index and could
be used for searching and retrieving raw samples. However, the TSID is never
exposed to the clients, i.e. it is for internal use only.
Instead, VictoriaMetrics maintains an inverted index that enables searching the raw samples by metric name, label name, and label value by mapping these values to the corresponding TSIDs.
VictoriaMetrics uses two types of inverted indexes:
- Global index. Searches using this index is performed across the entire retention period.
- Per-day index. This index stores mappings similar to ones in global index but also includes the date in each mapping. This speeds up data retrieval for queries within a shorter time range (which is often just the last day).
When the search query is executed, VictoriaMetrics decides which index to use based on the time range of the query:
- Per-day index is used if the search time range is 40 days or less.
- Global index is used for search queries with a time range greater than 40 days.
Mappings are added to the indexes during the data ingestion:
- In global index each mapping is created only once per retention period.
- In the per-day index each mapping is be created for each unique date that has been seen in the samples for the corresponding time series.
IndexDB respects retention period and once it is over, the indexes are dropped. For the new retention period, the indexes are gradually populated again as the new samples arrive.
Retention
Retention is configured with the -retentionPeriod command-line flag, which takes a number followed by a time unit
character - h(ours), d(ays), w(eeks), y(ears). If the time unit is not specified, a month (31 days) is assumed.
For instance, -retentionPeriod=3 means that the data will be stored for 3 months (93 days) and then deleted.
The default retention period is one month. The minimum retention period is 24h or 1d.
Data is split in per-month partitions inside <-storageDataPath>/data/{small,big} folders.
Data partitions outside the configured retention are deleted on the first day of the new month.
Each partition consists of one or more data parts. Data parts outside the configured retention
are eventually deleted during background merge.
The time range covered by data part is not limited by retention period unit. One data part can cover hours or days of
data. Hence, a data part can be deleted only when fully outside the configured retention.
See more about partitions and parts here.
The maximum disk space usage for a given -retentionPeriod is going to be (-retentionPeriod + 1) months.
For example, if -retentionPeriod is set to 1, data for January is deleted on March 1st.
It is safe to extend -retentionPeriod on existing data. If -retentionPeriod is set to a lower
value than before, then data outside the configured period will be eventually deleted.
VictoriaMetrics does not support indefinite retention, but you can specify an arbitrarily high duration, e.g. -retentionPeriod=100y.
Multiple retentions
Distinct retentions for distinct time series can be configured via retention filters in VictoriaMetrics enterprise.
Community version of VictoriaMetrics supports only a single retention, which can be configured via -retentionPeriod command-line flag. If you need multiple retentions in community version of VictoriaMetrics, then you may start multiple VictoriaMetrics instances with distinct values for the following flags:
-retentionPeriod-storageDataPath, so the data for each retention period is saved in a separate directory-httpListenAddr, so clients may reach VictoriaMetrics instance with proper retention
Then set up vmauth in front of VictoriaMetrics instances, so it could route requests from particular user to VictoriaMetrics with the desired retention.
Similar scheme can be applied for multiple tenants in VictoriaMetrics cluster. See these docs for multi-retention setup details.
Retention filters
Enterprise version of VictoriaMetrics supports e.g. retention filters,
which allow configuring multiple retentions for distinct sets of time series matching the configured series filters
via -retentionFilter command-line flag. This flag accepts filter:duration options, where filter must be
a valid series filter, while the duration
must contain valid retention for time series matching the given filter.
The duration of the -retentionFilter must be lower or equal to -retentionPeriod flag value.
If series doesn't match any configured -retentionFilter, then the retention configured via -retentionPeriod
command-line flag is applied to it. If series matches multiple configured retention filters, then the smallest retention is applied.
For example, the following config sets 3 days retention for time series with team="juniors" label,
30 days retention for time series with env="dev" or env="staging" label and 1 year retention for the remaining time series:
-retentionFilter='{team="juniors"}:3d' -retentionFilter='{env=~"dev|staging"}:30d' -retentionPeriod=1y
Important notes:
- The data outside the configured retention isn't deleted instantly - it is deleted eventually during background merges.
- The
-retentionFilterdoesn't remove old data from IndexDB until the configured -retentionPeriod. So the IndexDB size can grow big under high churn rate even for small retentions configured via-retentionFilter.
Retention filters configuration can be tested in enterprise version of vmui on the page Tools.Retention filters debug.
It is safe updating -retentionFilter during VictoriaMetrics restarts - the updated retention filters are applied eventually
to historical data.
See how to configure multiple retentions in VictoriaMetrics cluster.
See also downsampling.
Retention filters can be evaluated for free by downloading and using enterprise binaries from the releases page. See how to request a free trial license here.
Downsampling
VictoriaMetrics Enterprise supports multi-level downsampling via -downsampling.period=offset:interval command-line flag.
This command-line flag instructs leaving the last sample per each interval for time series
samples older than the offset. For example, -downsampling.period=30d:5m instructs leaving the last sample
per each 5-minute interval for samples older than 30 days, while the rest of samples are dropped.
The -downsampling.period command-line flag can be specified multiple times in order to apply different downsampling levels for different time ranges (aka multi-level downsampling).
For example, -downsampling.period=30d:5m,180d:1h instructs leaving the last sample per each 5-minute interval for samples older than 30 days,
while leaving the last sample per each 1-hour interval for samples older than 180 days.
VictoriaMetrics supports{{% available_from "v1.100.0" %}} configuring independent downsampling per different sets of time series
via -downsampling.period=filter:offset:interval syntax. In this case the given offset:interval downsampling is applied only to time series matching the given filter.
The filter can contain arbitrary series filter.
For example, -downsampling.period='{__name__=~"(node|process)_.*"}:1d:1m instructs VictoriaMetrics to deduplicate samples older than one day with one minute interval
only for time series with names starting with node_ or process_ prefixes.
The deduplication for other time series can be configured independently via additional -downsampling.period command-line flags.
Downsampling configuration can be tested in enterprise version of vmui on the page Tools.Downsampling filters debug.
If the time series doesn't match any filter, then it isn't downsampled. If the time series matches multiple filters, then the downsampling
for the first matching filter is applied. For example, -downsampling.period='{env="prod"}:1d:30s,{__name__=~"node_.*"}:1d:5m' de-duplicates
samples older than one day with 30 seconds interval across all the time series with env="prod" label,
even if their names start with node_ prefix. All the other time series with names starting with node_ prefix are de-duplicated with 5 minutes interval.
If downsampling shouldn't be applied to some time series matching the given filter, then pass -downsampling.period=filter:0s:0s command-line flag to VictoriaMetrics.
For example, if series with env="prod" label shouldn't be downsampled, then pass -downsampling.period='{env="prod"}:0s:0s' command-line flag in front of other -downsampling.period flags.
Downsampling is applied independently per each time series and leaves a single raw sample with the biggest timestamp on the configured interval, in the same way as deduplication does. It works the best for counters and histograms, as their values are always increasing. Downsampling gauges and summaries lose some changes within the downsampling interval, since only the last sample on the given interval is left and the rest of samples are dropped.
You can use recording rules or steaming aggregation to apply custom aggregation functions, like min/max/avg etc., in order to make gauges more resilient to downsampling.
Downsampling can reduce disk space usage and improve query performance if it is applied to time series with big number of samples per each series. The downsampling doesn't improve query performance and doesn't reduce disk space if the database contains big number of time series with small number of samples per each series, since downsampling doesn't reduce the number of time series. So there is little sense in applying downsampling to time series with high churn rate. In this case the majority of query time is spent on searching for the matching time series instead of processing the found samples. It is possible to use stream aggregation in vmagent or recording rules in vmalert in order to reduce the number of time series.
Downsampling is performed during background merges. It cannot be performed if there is not enough of free disk space or if vmstorage is in read-only mode.
Please, note that intervals of -downsampling.period must be multiples of each other.
In case deduplication is enabled, value of -dedup.minScrapeInterval command-line flag must also
be multiple of -downsampling.period intervals. This is required to ensure consistency of deduplication and downsampling results.
It is safe updating -downsampling.period during VictoriaMetrics restarts - the updated downsampling configuration will be
applied eventually to historical data during background merges.
See how to configure downsampling in VictoriaMetrics cluster.
See also retention filters.
The downsampling can be evaluated for free by downloading and using enterprise binaries from the releases page. See how to request a free trial license.
Multi-tenancy
Single-node VictoriaMetrics doesn't support multi-tenancy. Use the cluster version instead.
Scalability and cluster version
Though single-node VictoriaMetrics cannot scale to multiple nodes, it is optimized for resource usage - storage size / bandwidth / IOPS, RAM, CPU. This means that a single-node VictoriaMetrics may scale vertically and substitute a moderately sized cluster built with competing solutions such as Thanos, Uber M3, InfluxDB or TimescaleDB. See vertical scalability benchmarks.
So try single-node VictoriaMetrics at first and then switch to the cluster version if you still need horizontally scalable long-term remote storage for really large Prometheus deployments. Contact us for enterprise support.
Alerting
It is recommended using vmalert for alerting.
Additionally, alerting can be set up with the following tools:
- With Prometheus - see the corresponding docs.
- With Promxy - see the corresponding docs.
- With Grafana - see the corresponding docs.
mTLS protection
By default VictoriaMetrics accepts http requests at 8428 port (this port can be changed via -httpListenAddr command-line flags).
Enterprise version of VictoriaMetrics supports the ability to accept mTLS
requests at this port, by specifying -tls and -mtls command-line flags. For example, the following command runs VictoriaMetrics, which accepts only mTLS requests at port 8428:
./victoria-metrics -tls -mtls
By default system-wide TLS Root CA is used for verifying client certificates if -mtls command-line flag is specified.
It is possible to specify custom TLS Root CA via -mtlsCAFile command-line flag.
See also security docs.
Security
General security recommendations:
- All the VictoriaMetrics components must run in protected private networks without direct access from untrusted networks such as Internet. The exception is vmauth and vmgateway, which are intended for serving public requests and performing authorization with TLS termination.
- All the requests from untrusted networks to VictoriaMetrics components must go through auth proxy such as vmauth or vmgateway. The proxy must be set up with proper authentication and authorization.
- Prefer using lists of allowed API endpoints, while disallowing access to other endpoints when configuring vmauth in front of VictoriaMetrics components.
- Set reasonable
Strict-Transport-Securityheader value to all the components to mitigate MitM attacks, for example:max-age=31536000; includeSubDomains. See-http.header.hstsflag. - Set reasonable
Content-Security-Policyheader value to mitigate XSS attacks. See-http.header.cspflag. - Set reasonable
X-Frame-Optionsheader value to mitigate clickjacking attacks, for exampleDENY. See-http.header.frameOptionsflag.
VictoriaMetrics provides the following security-related command-line flags:
-tls,-tlsCertFileand-tlsKeyFilefor switching from HTTP to HTTPS at-httpListenAddr(TCP port 8428 is listened by default). Enterprise version of VictoriaMetrics supports automatic issuing of TLS certificates. See these docs.-mtlsand-mtlsCAFilefor enabling mTLS for requests to-httpListenAddr. See these docs.-httpAuth.usernameand-httpAuth.passwordfor protecting all the HTTP endpoints with HTTP Basic Authentication.-deleteAuthKeyfor protecting/api/v1/admin/tsdb/delete_seriesendpoint. See how to delete time series.-snapshotAuthKeyfor protecting/snapshot*endpoints. See how to work with snapshots.-forceFlushAuthKeyfor protecting/internal/force_flushendpoint. See these docs.-forceMergeAuthKeyfor protecting/internal/force_mergeendpoint. See force merge docs.-search.resetCacheAuthKeyfor protecting/internal/resetRollupResultCacheendpoint. See backfilling for more details.-reloadAuthKeyfor protecting/-/reloadendpoint, which is used for force reloading of-promscrape.config.-configAuthKeyfor protecting/configendpoint, since it may contain sensitive information such as passwords.-flagsAuthKeyfor protecting/flagsendpoint.-pprofAuthKeyfor protecting/debug/pprof/*endpoints, which can be used for profiling.-denyQueryTracingfor disallowing query tracing.-http.header.hsts,-http.header.csp, and-http.header.frameOptionsfor servingStrict-Transport-Security,Content-Security-PolicyandX-Frame-OptionsHTTP response headers.
Explicitly set internal network interface for TCP and UDP ports for data ingestion with Graphite and OpenTSDB formats.
For example, substitute -graphiteListenAddr=:2003 with -graphiteListenAddr=<internal_iface_ip>:2003. This protects from unexpected requests from untrusted network interfaces.
See also security recommendation for VictoriaMetrics cluster and the general security page at VictoriaMetrics website.
Automatic issuing of TLS certificates
All the VictoriaMetrics Enterprise components support automatic issuing of TLS certificates for public HTTPS server running at -httpListenAddr
via Let's Encrypt service. The following command-line flags must be set in order to enable automatic issuing of TLS certificates:
-httpListenAddrmust be set for listening TCP port443. For example,-httpListenAddr=:443. This port must be accessible by the Let's Encrypt service.-tlsmust be set in order to accept HTTPS requests at-httpListenAddr. Note that-tlcCertFileand-tlsKeyFilearen't needed when automatic TLS certificate issuing is enabled.-tlsAutocertHostsmust be set to comma-separated list of hosts, which can be reached via-httpListenAddr. TLS certificates are automatically issued for these hosts.-tlsAutocertEmailmust be set to contact email for the issued TLS certificates.-tlsAutocertCacheDirmay be set to the directory path for persisting the issued TLS certificates between VictoriaMetrics restarts. If this flag isn't set, then TLS certificates are re-issued on every restart.
This functionality can be evaluated for free according to these docs.
See also security recommendations.
Tuning
- No need in tuning for VictoriaMetrics - it uses reasonable defaults for command-line flags, which are automatically adjusted for the available CPU and RAM resources.
- No need in tuning for Operating System - VictoriaMetrics is optimized for default OS settings. The only option is increasing the limit on the number of open files in the OS. The recommendation is not specific for VictoriaMetrics only but also for any service which handles many HTTP connections and stores data on disk.
- VictoriaMetrics is a write-heavy application and its performance depends on disk performance. So be careful with other applications or utilities (like fstrim) which could exhaust disk resources.
- The recommended filesystem is
ext4, the recommended persistent storage is persistent HDD-based disk on GCP, since it is protected from hardware failures via internal replication and it can be resized on the fly. If you plan to store more than 1TB of data onext4partition or plan extending it to more than 16TB, then the following options are recommended to pass tomkfs.ext4:
mkfs.ext4 ... -O 64bit,huge_file,extent -T huge
Monitoring
VictoriaMetrics exports internal metrics in Prometheus exposition format at /metrics page.
These metrics can be scraped via vmagent or any other Prometheus-compatible scraper.
If you use Google Cloud Managed Prometheus for scraping metrics from VictoriaMetrics components, then pass -metrics.exposeMetadata
command-line to them, so they add TYPE and HELP comments per each exposed metric at /metrics page.
See these docs for details.
Alternatively, single-node VictoriaMetrics can self-scrape the metrics when -selfScrapeInterval command-line flag is
set to duration greater than 0. For example, -selfScrapeInterval=10s would enable self-scraping of /metrics page
with 10 seconds interval.
Please note, never use loadbalancer address for scraping metrics. All the monitored components should be scraped directly by their address.
Official Grafana dashboards available for single-node and clustered VictoriaMetrics. See an alternative dashboard for clustered VictoriaMetrics created by community.
Graphs on the dashboards contain useful hints - hover the i icon in the top left corner of each graph to read it.
We recommend setting up alerts via vmalert or via Prometheus.
VictoriaMetrics exposes currently running queries and their execution times at active queries page.
VictoriaMetrics exposes queries, which take the most time to execute, at top queries page.
See also VictoriaMetrics Monitoring and troubleshooting docs.
TSDB stats
VictoriaMetrics returns TSDB stats at /api/v1/status/tsdb page in the way similar to Prometheus - see these Prometheus docs. VictoriaMetrics accepts the following optional query args at /api/v1/status/tsdb page:
topN=NwhereNis the number of top entries to return in the response. By default top 10 entries are returned.date=YYYY-MM-DDwhereYYYY-MM-DDis the date for collecting the stats. By default the stats is collected for the current day. Passdate=1970-01-01in order to collect global stats across all the days.focusLabel=LABEL_NAMEreturns label values with the highest number of time series for the givenLABEL_NAMEin theseriesCountByFocusLabelValuelist.match[]=SELECTORwhereSELECTORis an arbitrary time series selector for series to take into account during stats calculation. By default all the series are taken into account.extra_label=LABEL=VALUE. See these docs for more details.
In cluster version of VictoriaMetrics each vmstorage tracks the stored time series individually. vmselect requests stats via /api/v1/status/tsdb API from each vmstorage node and merges the results by summing per-series stats. This may lead to inflated values when samples for the same time series are spread across multiple vmstorage nodes due to replication or rerouting.
VictoriaMetrics provides an UI on top of /api/v1/status/tsdb - see cardinality explorer docs.
Query tracing
VictoriaMetrics supports query tracing, which can be used for determining bottlenecks during query processing.
This is like EXPLAIN ANALYZE from Postgresql.
Query tracing can be enabled for a specific query by passing trace=1 query arg.
In this case VictoriaMetrics puts query trace into trace field in the output JSON.
For example, the following command:
curl http://localhost:8428/api/v1/query_range -d 'query=2*rand()' -d 'start=-1h' -d 'step=1m' -d 'trace=1' | jq '.trace'
would return the following trace:
{
"duration_msec": 0.099,
"message": "/api/v1/query_range: start=1654034340000, end=1654037880000, step=60000, query=\"2*rand()\": series=1",
"children": [
{
"duration_msec": 0.034,
"message": "eval: query=2 * rand(), timeRange=[1654034340000..1654037880000], step=60000, mayCache=true: series=1, points=60, pointsPerSeries=60",
"children": [
{
"duration_msec": 0.032,
"message": "binary op \"*\": series=1",
"children": [
{
"duration_msec": 0.009,
"message": "eval: query=2, timeRange=[1654034340000..1654037880000], step=60000, mayCache=true: series=1, points=60, pointsPerSeries=60"
},
{
"duration_msec": 0.017,
"message": "eval: query=rand(), timeRange=[1654034340000..1654037880000], step=60000, mayCache=true: series=1, points=60, pointsPerSeries=60",
"children": [
{
"duration_msec": 0.015,
"message": "transform rand(): series=1"
}
]
}
]
}
]
},
{
"duration_msec": 0.004,
"message": "sort series by metric name and labels"
},
{
"duration_msec": 0.044,
"message": "generate /api/v1/query_range response for series=1, points=60"
}
]
}
All the durations and timestamps in traces are in milliseconds.
Query tracing is allowed by default. It can be denied by passing -denyQueryTracing command-line flag to VictoriaMetrics.
VMUI provides an UI:
- for query tracing - just click
Trace querycheckbox and re-run the query in order to investigate its' trace. - for exploring custom trace - go to the tab
Trace analyzerand upload or paste JSON with trace information.
Cardinality limiter
By default VictoriaMetrics doesn't limit the number of stored time series. The limit can be enforced by setting the following command-line flags:
-storage.maxHourlySeries- limits the number of time series that can be added during the last hour. Useful for limiting the number of active time series.-storage.maxDailySeries- limits the number of time series that can be added during the last day. Useful for limiting daily churn rate.
Both limits can be set simultaneously. If any of these limits is reached, then incoming samples for new time series are dropped. A sample of dropped series is put in the log with WARNING level.
The exceeded limits can be monitored with the following metrics:
-
vm_hourly_series_limit_rows_dropped_total- the number of metrics dropped due to exceeded hourly limit on the number of unique time series. -
vm_hourly_series_limit_max_series- the hourly series limit set via-storage.maxHourlySeriescommand-line flag. -
vm_hourly_series_limit_current_series- the current number of unique series during the last hour. The following query can be useful for alerting when the number of unique series during the last hour exceeds 90% of the-storage.maxHourlySeries:vm_hourly_series_limit_current_series / vm_hourly_series_limit_max_series > 0.9 -
vm_daily_series_limit_rows_dropped_total- the number of metrics dropped due to exceeded daily limit on the number of unique time series. -
vm_daily_series_limit_max_series- the daily series limit set via-storage.maxDailySeriescommand-line flag. -
vm_daily_series_limit_current_series- the current number of unique series during the last day. The following query can be useful for alerting when the number of unique series during the last day exceeds 90% of the-storage.maxDailySeries:vm_daily_series_limit_current_series / vm_daily_series_limit_max_series > 0.9
These limits are approximate, so VictoriaMetrics can underflow/overflow the limit by a small percentage (usually less than 1%).
See also more advanced cardinality limiter in vmagent and cardinality explorer docs.
Troubleshooting
-
It is recommended to use default command-line flag values (i.e. don't set them explicitly) until the need of tweaking these flag values arises.
-
It is recommended inspecting logs during troubleshooting, since they may contain useful information.
-
It is recommended upgrading to the latest available release from this page, since the encountered issue could be already fixed there.
-
It is recommended to have at least 50% of spare resources for CPU, disk IO and RAM, so VictoriaMetrics could handle short spikes in the workload without performance issues.
-
VictoriaMetrics requires free disk space for merging data files to bigger ones. It may slow down when there is no enough free space left. So make sure
-storageDataPathdirectory has at least 20% of free space. The remaining amount of free space can be monitored viavm_free_disk_space_bytesmetric. The total size of data stored on the disk can be monitored via sum ofvm_data_size_bytesmetrics. -
If you run VictoriaMetrics on a host with 16 or more CPU cores, then it may be needed to tune the
-search.maxWorkersPerQuerycommand-line flag in order to improve query performance. If VictoriaMetrics serves big number of concurrentselectqueries, then try reducing the value for this flag. If VictoriaMetrics serves heavy queries, which select>10Kof time series and/or process>100Mof raw samples per query, then try setting the value for this flag to the number of available CPU cores. -
VictoriaMetrics buffers incoming data in memory for up to a few seconds before flushing it to persistent storage. This may lead to the following "issues":
- Data becomes available for querying in a few seconds after inserting. It is possible to flush in-memory buffers to searchable parts
by requesting
/internal/force_flushhttp handler. This handler is mostly needed for testing and debugging purposes. - The last few seconds of inserted data may be lost on unclean shutdown (i.e. OOM,
kill -9or hardware reset). The-inmemoryDataFlushIntervalcommand-line flag allows controlling the frequency of in-memory data flush to persistent storage. See storage docs and this article for more details.
- Data becomes available for querying in a few seconds after inserting. It is possible to flush in-memory buffers to searchable parts
by requesting
-
If VictoriaMetrics works slowly and eats more than a CPU core per 100K ingested data points per second, then it is likely you have too many active time series for the current amount of RAM. VictoriaMetrics exposes
vm_slow_*metrics such asvm_slow_row_inserts_totalandvm_slow_metric_name_loads_total, which could be used as an indicator of low amounts of RAM. It is recommended increasing the amount of RAM on the node with VictoriaMetrics in order to improve ingestion and query performance in this case. -
If the order of labels for the same metrics can change over time (e.g. if
metric{k1="v1",k2="v2"}may becomemetric{k2="v2",k1="v1"}), then it is recommended running VictoriaMetrics with-sortLabelscommand-line flag in order to reduce memory usage and CPU usage. -
VictoriaMetrics prioritizes data ingestion over data querying. So if it has no enough resources for data ingestion, then data querying may slow down significantly.
-
If VictoriaMetrics doesn't work because of certain parts are corrupted due to disk errors, then just remove directories with broken parts. It is safe removing subdirectories under
<-storageDataPath>/data/{big,small}/YYYY_MMdirectories when VictoriaMetrics isn't running. This recovers VictoriaMetrics at the cost of data loss stored in the deleted broken parts. The names of broken parts should be present in the error message. If you see that error message is truncated and doesn't contain all the information try increasing-loggerMaxArgLencmd-line flag to higher values to avoid error messages truncation. -
If you see gaps on the graphs, try resetting the cache by sending request to
/internal/resetRollupResultCache. If this removes gaps on the graphs, then it is likely data with timestamps older than-search.cacheTimestampOffsetis ingested into VictoriaMetrics. Make sure that data sources have synchronized time with VictoriaMetrics.If the gaps are related to irregular intervals between samples, then try adjusting
-search.minStalenessIntervalcommand-line flag to value close to the maximum interval between samples. -
If you are switching from InfluxDB or TimescaleDB, then it may be needed to set
-search.setLookbackToStepcommand-line flag. This suppresses default gap filling algorithm used by VictoriaMetrics - by default it assumes each time series is continuous instead of discrete, so it fills gaps between real samples with regular intervals. -
Metrics and labels leading to high cardinality or high churn rate can be determined via cardinality explorer and via /api/v1/status/tsdb endpoint.
-
New time series can be logged if
-logNewSeriescommand-line flag is passed to VictoriaMetrics. -
VictoriaMetrics limits the number of labels per each metric with
-maxLabelsPerTimeseriescommand-line flag and drops superfluous labels. This prevents from ingesting metrics with too many labels. It is recommended monitoringvm_metrics_with_dropped_labels_totalmetric in order to determine whether-maxLabelsPerTimeseriesmust be adjusted for your workload. -
If you store Graphite metrics like
foo.bar.bazin VictoriaMetrics, then{__graphite__="foo.*.baz"}filter can be used for selecting such metrics. See these docs for details. You can also query Graphite metrics with Graphite querying API. -
VictoriaMetrics ignores
NaNvalues during data ingestion.
See also:
Push metrics
All the VictoriaMetrics components support pushing their metrics exposed at /metrics page to remote storage in Prometheus text exposition format.
This functionality may be used instead of classic Prometheus-like metrics scraping
if VictoriaMetrics components are located in isolated networks, so they cannot be scraped by local vmagent.
The following command-line flags are related to pushing metrics from VictoriaMetrics components:
-pushmetrics.url- the url to push metrics to. For example,-pushmetrics.url=http://victoria-metrics:8428/api/v1/import/prometheusinstructs to push internal metrics to/api/v1/import/prometheusendpoint according to these docs. The-pushmetrics.urlcan be specified multiple times. In this case metrics are pushed to all the specified urls. The url can contain basic auth params in the formhttp://user:pass@hostname/api/v1/import/prometheus. Metrics are pushed to the provided-pushmetrics.urlin a compressed form withContent-Encoding: gziprequest header. This allows reducing the required network bandwidth for metrics push. The compression can be disabled by passing-pushmetrics.disableCompressioncommand-line flag.-pushmetrics.extraLabel- labels to add to all the metrics before sending them to every-pushmetrics.url. Each label must be specified in the formatlabel="value". It is OK to specify multiple-pushmetrics.extraLabelcommand-line flags. In this case all the specified labels are added to all the metrics before sending them to all the configured-pushmetrics.urladdresses.-pushmetrics.interval- the interval between pushes. By default it is set to 10 seconds.-pushmetrics.header- an optional HTTP header to send to every-pushmetrics.url. For example,-pushmetrics.header='Authorization: Basic foo'instructs to sendAuthorization: Basic fooHTTP header with every request to every-pushmetrics.url. It is possible to set multiple-pushmetrics.headercommand-line flags for sending multiple different HTTP headers to-pushmetrics.url.
For example, the following command instructs VictoriaMetrics to push metrics from /metrics page to https://maas.victoriametrics.com/api/v1/import/prometheus
with user:pass Basic auth. The instance="foobar" and job="vm" labels
are added to all the metrics before sending them to the remote storage:
/path/to/victoria-metrics \
-pushmetrics.url=https://user:pass@maas.victoriametrics.com/api/v1/import/prometheus \
-pushmetrics.extraLabel='instance="foobar"' \
-pushmetrics.extraLabel='job="vm"'
Cache removal
VictoriaMetrics uses various internal caches. These caches are stored to <-storageDataPath>/cache directory during graceful shutdown
(e.g. when VictoriaMetrics is stopped by sending SIGINT signal). The caches are read on the next VictoriaMetrics startup.
Sometimes it is needed to remove such caches on the next startup. This can be done in the following ways:
- By manually removing the
<-storageDataPath>/cachedirectory when VictoriaMetrics is stopped. - By placing
reset_cache_on_startupfile inside the<-storageDataPath>/cachedirectory before the restart of VictoriaMetrics. In this case VictoriaMetrics will automatically remove all the caches on the next start. See this issue for details.
It is also possible removing rollup result cache on startup by passing -search.resetRollupResultCacheOnStartup command-line flag to VictoriaMetrics.
Rollup result cache
VictoriaMetrics caches query responses by default. This allows increasing performance for repeated queries
to /api/v1/query and /api/v1/query_range
with the increasing time, start and end query args.
This cache may work incorrectly when ingesting historical data into VictoriaMetrics. See these docs for details.
The rollup cache can be disabled either globally by running VictoriaMetrics with -search.disableCache command-line flag
or on a per-query basis by passing nocache=1 query arg to /api/v1/query and /api/v1/query_range.
See also cache removal docs.
Cache tuning
VictoriaMetrics uses various in-memory caches for faster data ingestion and query performance.
The following metrics for each type of cache are exported at /metrics page:
vm_cache_size_bytes- the actual cache sizevm_cache_size_max_bytes- cache size limitvm_cache_requests_total- the number of requests to the cachevm_cache_misses_total- the number of cache missesvm_cache_entries- the number of entries in the cache
Both Grafana dashboards for single-node VictoriaMetrics
and clustered VictoriaMetrics
contain Caches section with cache metrics visualized. The panels show the current
memory usage by each type of cache, and also a cache hit rate. If hit rate is close to 100%
then cache efficiency is already very high and does not need any tuning.
The panel Cache usage % in Troubleshooting section shows the percentage of used cache size
from the allowed size by type. If the percentage is below 100%, then no further tuning needed.
Please note, default cache sizes were carefully adjusted accordingly to the most practical scenarios and workloads. Change the defaults only if you understand the implications and vmstorage has enough free memory to accommodate new cache sizes.
To override the default values see command-line flags with -storage.cacheSize prefix.
See the full description of flags here.
Data migration
From VictoriaMetrics
The simplest way to migrate data from one single-node (source) to another (destination), or from one vmstorage node to another do the following:
- Stop the VictoriaMetrics (source) with
kill -INT; - Copy (via rsync or any other tool) the entire folder specified
via
-storageDataPathfrom the source node to the empty folder at the destination node. - Once copy is done, stop the VictoriaMetrics (destination) with
kill -INTand verify that its-storageDataPathpoints to the copied folder from p.2; - Start the VictoriaMetrics (destination). The copied data should be now available.
Things to consider when copying data:
- Data formats between single-node and vmstorage node aren't compatible and can't be copied.
- Copying data folder means complete replacement of the previous data on destination VictoriaMetrics.
For more complex scenarios like single-to-cluster, cluster-to-single, re-sharding or migrating only a fraction of data - see vmctl. Migrating data from VictoriaMetrics.
From other systems
Use vmctl for data migration. It supports the following data migration types:
- From Prometheus to VictoriaMetrics
- From InfluxDB to VictoriaMetrics
- From VictoriaMetrics to VictoriaMetrics
- From OpenTSDB to VictoriaMetrics
See vmctl docs for more details.
Backfilling
VictoriaMetrics accepts historical data in arbitrary order of time via any supported ingestion method.
See how to backfill data with recording rules in vmalert.
Make sure that configured -retentionPeriod covers timestamps for the backfilled data.
It is recommended disabling query cache with -search.disableCache command-line flag when writing
historical data with timestamps from the past, since the cache assumes that the data is written with
the current timestamps. Query cache can be enabled after the backfilling is complete.
An alternative solution is to query /internal/resetRollupResultCache after the backfilling is complete. This will reset the query cache, which could contain incomplete data cached during the backfilling.
Yet another solution is to increase -search.cacheTimestampOffset flag value in order to disable caching
for data with timestamps close to the current time. Single-node VictoriaMetrics automatically resets response
cache when samples with timestamps older than now - search.cacheTimestampOffset are ingested to it.
Data updates
VictoriaMetrics doesn't support updating already existing sample values to new ones. It stores all the ingested data points for the same time series with identical timestamps. While it is possible substituting old time series with new time series via removal of old time series and then writing new time series, this approach should be used only for one-off updates. It shouldn't be used for frequent updates because of non-zero overhead related to data removal.
Replication
Single-node VictoriaMetrics doesn't support application-level replication. Use cluster version instead. See these docs for details.
Storage-level replication may be offloaded to durable persistent storage such as Google Cloud disks.
See also high availability docs and backup docs.
Backups
VictoriaMetrics supports backups via vmbackup and vmrestore tools. We also provide vmbackupmanager tool for enterprise subscribers. Enterprise binaries can be downloaded and evaluated for free from the releases page. See how to request a free trial license here.
vmalert
A single-node VictoriaMetrics is capable of proxying requests to vmalert
when -vmalert.proxyURL flag is set. Use this feature for the following cases:
- for proxying requests from Grafana Alerting UI;
- for accessing vmalerts UI through single-node VictoriaMetrics Web interface.
For accessing vmalerts UI through single-node VictoriaMetrics configure -vmalert.proxyURL flag and visit
http://<victoriametrics-addr>:8428/vmalert/ link.
Benchmarks
Note, that vendors (including VictoriaMetrics) are often biased when doing such tests. E.g. they try highlighting the best parts of their product, while highlighting the worst parts of competing products. So we encourage users and all independent third parties to conduct their benchmarks for various products they are evaluating in production and publish the results.
As a reference, please see benchmarks conducted by VictoriaMetrics team. Please also see the helm chart for running ingestion benchmarks based on node_exporter metrics.
Profiling
VictoriaMetrics provides handlers for collecting the following Go profiles:
- Memory profile. It can be collected with the following command (replace
0.0.0.0with hostname if needed):
curl http://0.0.0.0:8428/debug/pprof/heap > mem.pprof
- CPU profile. It can be collected with the following command (replace
0.0.0.0with hostname if needed):
curl http://0.0.0.0:8428/debug/pprof/profile > cpu.pprof
The command for collecting CPU profile waits for 30 seconds before returning.
The collected profiles may be analyzed with go tool pprof. It is safe sharing the collected profiles from security point of view, since they do not contain sensitive information.
Integrations
- go-graphite/carbonapi can use VictoriaMetrics as time series backend. See this example.
- netdata can push data into VictoriaMetrics via
Prometheus remote_write API. See these docs. - vmalert-cli - a CLI application for managing vmalert.
Third-party contributions
- Prometheus -> VictoriaMetrics exporter #1
- Prometheus -> VictoriaMetrics exporter #2
- Prometheus Oauth proxy - see this article for details.
Contacts
Contact us with any questions regarding VictoriaMetrics at info@victoriametrics.com.
Community and contributions
Feel free asking any questions regarding VictoriaMetrics:
If you like VictoriaMetrics and want to contribute, then please read these docs.
Reporting bugs
Report bugs and propose new features here.
Documentation
VictoriaMetrics documentation is available at https://docs.victoriametrics.com/.
It is built from *.md files located in docs folder
and gets automatically updated once changes are merged to master branch.
To update the documentation follow the steps below:
- Fork
VictoriaMetrics repo and apply changes to the docs:
- To update the main page modify this file.
- To update other pages, apply changes to the corresponding file in docs folder.
- If your changes contain an image then see images in documentation.
- Create a pull request with proposed changes and wait for it to be merged. See contributing.
Requirements for changes to docs:
- Keep backward compatibility of existing links. Avoid changing anchors or deleting pages as they could have been used or posted in other docs, GitHub issues, stackoverlow answers, etc.
- Keep docs clear, concise and simple. Try using as simple wording as possible, without sacrificing clarity.
- Keep docs consistent. When modifying existing docs, verify that other places referencing to this doc are still relevant.
- Prefer improving the existing docs instead of adding new ones.
- Use absolute links. This simplifies moving docs between different files.
Periodically run make spellcheck - this command detects spelling errors at docs/ folder. Please fix the found spelling errors
and commit the fixes in a separate commit.
Images in documentation
Please, keep image size and number of images per single page low. Keep the docs page as lightweight as possible.
Image files must be placed in the same folder as the doc itself and they must have the same prefix as the doc filename.
For example, all the images for docs/foo/bar.md should have filenames starting from docs/foo/bar.
This simplifies lifetime management of the images:
- when the corresponding doc is removed, then it is clear how to remove the associated images
- when the corresponding doc is renamed, then it is clear how to rename the associated images.
If the page needs to have many images, consider using WEB-optimized image format webp.
When adding a new doc with many images use webp format right away. Or use a Makefile command below to
convert already existing images at docs folder automatically to web format:
make docs-images-to-webp
Once conversion is done, update the path to images in your docs and verify everything is correct.
VictoriaMetrics Logo
Zip contains three folders with different image orientations (main color and inverted version).
Files included in each folder:
- 2 JPEG Preview files
- 2 PNG Preview files with transparent background
- 2 EPS Adobe Illustrator EPS10 files
Logo Usage Guidelines
Font used
- Lato Black
- Lato Regular
Color Palette
We kindly ask
- Please don't use any other font instead of suggested.
- To keep enough clear space around the logo.
- Do not change spacing, alignment, or relative locations of the design elements.
- Do not change the proportions for any of the design elements or the design itself. You may resize as needed but must retain all proportions.
List of command-line flags
Pass -help to VictoriaMetrics in order to see the list of supported command-line flags with their description:
-bigMergeConcurrency int
Deprecated: this flag does nothing
-blockcache.missesBeforeCaching int
The number of cache misses before putting the block into cache. Higher values may reduce indexdb/dataBlocks cache size at the cost of higher CPU and disk read usage (default 2)
-cacheExpireDuration duration
Items are removed from in-memory caches after they aren't accessed for this duration. Lower values may reduce memory usage at the cost of higher CPU usage. See also -prevCacheRemovalPercent (default 30m0s)
-configAuthKey value
Authorization key for accessing /config page. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -configAuthKey=file:///abs/path/to/file or -configAuthKey=file://./relative/path/to/file . Flag value can be read from the given http/https url when using -configAuthKey=http://host/path or -configAuthKey=https://host/path
-csvTrimTimestamp duration
Trim timestamps when importing csv data to this duration. Minimum practical duration is 1ms. Higher duration (i.e. 1s) may be used for reducing disk space usage for timestamp data (default 1ms)
-datadog.maxInsertRequestSize size
The maximum size in bytes of a single DataDog POST request to /datadog/api/v2/series
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 67108864)
-datadog.sanitizeMetricName
Sanitize metric names for the ingested DataDog data to comply with DataDog behaviour described at https://docs.datadoghq.com/metrics/custom_metrics/#naming-custom-metrics (default true)
-dedup.minScrapeInterval duration
Leave only the last sample in every time series per each discrete interval equal to -dedup.minScrapeInterval > 0. See also -streamAggr.dedupInterval and https://docs.victoriametrics.com/#deduplication
-deleteAuthKey value
authKey for metrics' deletion via /api/v1/admin/tsdb/delete_series and /tags/delSeries
Flag value can be read from the given file when using -deleteAuthKey=file:///abs/path/to/file or -deleteAuthKey=file://./relative/path/to/file . Flag value can be read from the given http/https url when using -deleteAuthKey=http://host/path or -deleteAuthKey=https://host/path
-denyQueriesOutsideRetention
Whether to deny queries outside the configured -retentionPeriod. When set, then /api/v1/query_range would return '503 Service Unavailable' error for queries with 'from' value outside -retentionPeriod. This may be useful when multiple data sources with distinct retentions are hidden behind query-tee
-denyQueryTracing
Whether to disable the ability to trace queries. See https://docs.victoriametrics.com/#query-tracing
-downsampling.period array
Comma-separated downsampling periods in the format 'offset:period'. For example, '30d:10m' instructs to leave a single sample per 10 minutes for samples older than 30 days. When setting multiple downsampling periods, it is necessary for the periods to be multiples of each other. See https://docs.victoriametrics.com/#downsampling for details. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-dryRun
Whether to check config files without running VictoriaMetrics. The following config files are checked: -promscrape.config, -relabelConfig and -streamAggr.config. Unknown config entries aren't allowed in -promscrape.config by default. This can be changed with -promscrape.config.strictParse=false command-line flag
-enableTCP6
Whether to enable IPv6 for listening and dialing. By default, only IPv4 TCP and UDP are used
-envflag.enable
Whether to enable reading flags from environment variables in addition to the command line. Command line flag values have priority over values from environment vars. Flags are read only from the command line if this flag isn't set. See https://docs.victoriametrics.com/#environment-variables for more details
-envflag.prefix string
Prefix for environment variables if -envflag.enable is set
-eula
Deprecated, please use -license or -licenseFile flags instead. By specifying this flag, you confirm that you have an enterprise license and accept the ESA https://victoriametrics.com/legal/esa/ . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/enterprise/
-filestream.disableFadvise
Whether to disable fadvise() syscall when reading large data files. The fadvise() syscall prevents from eviction of recently accessed data from OS page cache during background merges and backups. In some rare cases it is better to disable the syscall if it uses too much CPU
-finalMergeDelay duration
Deprecated: this flag does nothing
-flagsAuthKey value
Auth key for /flags endpoint. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -flagsAuthKey=file:///abs/path/to/file or -flagsAuthKey=file://./relative/path/to/file . Flag value can be read from the given http/https url when using -flagsAuthKey=http://host/path or -flagsAuthKey=https://host/path
-forceFlushAuthKey value
authKey, which must be passed in query string to /internal/force_flush pages
Flag value can be read from the given file when using -forceFlushAuthKey=file:///abs/path/to/file or -forceFlushAuthKey=file://./relative/path/to/file . Flag value can be read from the given http/https url when using -forceFlushAuthKey=http://host/path or -forceFlushAuthKey=https://host/path
-forceMergeAuthKey value
authKey, which must be passed in query string to /internal/force_merge pages
Flag value can be read from the given file when using -forceMergeAuthKey=file:///abs/path/to/file or -forceMergeAuthKey=file://./relative/path/to/file . Flag value can be read from the given http/https url when using -forceMergeAuthKey=http://host/path or -forceMergeAuthKey=https://host/path
-fs.disableMmap
Whether to use pread() instead of mmap() for reading data files. By default, mmap() is used for 64-bit arches and pread() is used for 32-bit arches, since they cannot read data files bigger than 2^32 bytes in memory. mmap() is usually faster for reading small data chunks than pread()
-graphite.sanitizeMetricName
Sanitize metric names for the ingested Graphite data. See https://docs.victoriametrics.com/#how-to-send-data-from-graphite-compatible-agents-such-as-statsd
-graphiteListenAddr string
TCP and UDP address to listen for Graphite plaintext data. Usually :2003 must be set. Doesn't work if empty. See also -graphiteListenAddr.useProxyProtocol
-graphiteListenAddr.useProxyProtocol
Whether to use proxy protocol for connections accepted at -graphiteListenAddr . See https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt
-graphiteTrimTimestamp duration
Trim timestamps for Graphite data to this duration. Minimum practical duration is 1s. Higher duration (i.e. 1m) may be used for reducing disk space usage for timestamp data (default 1s)
-http.connTimeout duration
Incoming connections to -httpListenAddr are closed after the configured timeout. This may help evenly spreading load among a cluster of services behind TCP-level load balancer. Zero value disables closing of incoming connections (default 2m0s)
-http.disableResponseCompression
Disable compression of HTTP responses to save CPU resources. By default, compression is enabled to save network bandwidth
-http.header.csp string
Value for 'Content-Security-Policy' header, recommended: "default-src 'self'"
-http.header.frameOptions string
Value for 'X-Frame-Options' header
-http.header.hsts string
Value for 'Strict-Transport-Security' header, recommended: 'max-age=31536000; includeSubDomains'
-http.idleConnTimeout duration
Timeout for incoming idle http connections (default 1m0s)
-http.maxGracefulShutdownDuration duration
The maximum duration for a graceful shutdown of the HTTP server. A highly loaded server may require increased value for a graceful shutdown (default 7s)
-http.pathPrefix string
An optional prefix to add to all the paths handled by http server. For example, if '-http.pathPrefix=/foo/bar' is set, then all the http requests will be handled on '/foo/bar/*' paths. This may be useful for proxied requests. See https://www.robustperception.io/using-external-urls-and-proxies-with-prometheus
-http.shutdownDelay duration
Optional delay before http server shutdown. During this delay, the server returns non-OK responses from /health page, so load balancers can route new requests to other servers
-httpAuth.password value
Password for HTTP server's Basic Auth. The authentication is disabled if -httpAuth.username is empty
Flag value can be read from the given file when using -httpAuth.password=file:///abs/path/to/file or -httpAuth.password=file://./relative/path/to/file . Flag value can be read from the given http/https url when using -httpAuth.password=http://host/path or -httpAuth.password=https://host/path
-httpAuth.username string
Username for HTTP server's Basic Auth. The authentication is disabled if empty. See also -httpAuth.password
-httpListenAddr array
TCP addresses to listen for incoming http requests. See also -tls and -httpListenAddr.useProxyProtocol
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-httpListenAddr.useProxyProtocol array
Whether to use proxy protocol for connections accepted at the corresponding -httpListenAddr . See https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt . With enabled proxy protocol http server cannot serve regular /metrics endpoint. Use -pushmetrics.url for metrics pushing
Supports array of values separated by comma or specified via multiple flags.
Empty values are set to false.
-import.maxLineLen size
The maximum length in bytes of a single line accepted by /api/v1/import; the line length can be limited with 'max_rows_per_line' query arg passed to /api/v1/export
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 10485760)
-influx.databaseNames array
Comma-separated list of database names to return from /query and /influx/query API. This can be needed for accepting data from Telegraf plugins such as https://github.com/fangli/fluent-plugin-influxdb
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-influx.maxLineSize size
The maximum size in bytes for a single InfluxDB line during parsing. Applicable for stream mode only. See https://docs.victoriametrics.com/#how-to-send-data-from-influxdb-compatible-agents-such-as-telegraf
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 262144)
-influx.maxRequestSize size
The maximum size in bytes of a single InfluxDB request. Applicable for batch mode only. See https://docs.victoriametrics.com/#how-to-send-data-from-influxdb-compatible-agents-such-as-telegraf
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 67108864)
-influxDBLabel string
Default label for the DB name sent over '?db={db_name}' query parameter (default "db")
-influxListenAddr string
TCP and UDP address to listen for InfluxDB line protocol data. Usually :8089 must be set. Doesn't work if empty. This flag isn't needed when ingesting data over HTTP - just send it to http://<victoriametrics>:8428/write . See also -influxListenAddr.useProxyProtocol
-influxListenAddr.useProxyProtocol
Whether to use proxy protocol for connections accepted at -influxListenAddr . See https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt
-influxMeasurementFieldSeparator string
Separator for '{measurement}{separator}{field_name}' metric name when inserted via InfluxDB line protocol (default "_")
-influxSkipMeasurement
Uses '{field_name}' as a metric name while ignoring '{measurement}' and '-influxMeasurementFieldSeparator'
-influxSkipSingleField
Uses '{measurement}' instead of '{measurement}{separator}{field_name}' for metric name if InfluxDB line contains only a single field
-influxTrimTimestamp duration
Trim timestamps for InfluxDB line protocol data to this duration. Minimum practical duration is 1ms. Higher duration (i.e. 1s) may be used for reducing disk space usage for timestamp data (default 1ms)
-inmemoryDataFlushInterval duration
The interval for guaranteed saving of in-memory data to disk. The saved data survives unclean shutdowns such as OOM crash, hardware reset, SIGKILL, etc. Bigger intervals may help increase the lifetime of flash storage with limited write cycles (e.g. Raspberry PI). Smaller intervals increase disk IO load. Minimum supported value is 1s (default 5s)
-insert.maxQueueDuration duration
The maximum duration to wait in the queue when -maxConcurrentInserts concurrent insert requests are executed (default 1m0s)
-internStringCacheExpireDuration duration
The expiry duration for caches for interned strings. See https://en.wikipedia.org/wiki/String_interning . See also -internStringMaxLen and -internStringDisableCache (default 6m0s)
-internStringDisableCache
Whether to disable caches for interned strings. This may reduce memory usage at the cost of higher CPU usage. See https://en.wikipedia.org/wiki/String_interning . See also -internStringCacheExpireDuration and -internStringMaxLen
-internStringMaxLen int
The maximum length for strings to intern. A lower limit may save memory at the cost of higher CPU usage. See https://en.wikipedia.org/wiki/String_interning . See also -internStringDisableCache and -internStringCacheExpireDuration (default 500)
-license string
License key for VictoriaMetrics Enterprise. See https://victoriametrics.com/products/enterprise/ . Trial Enterprise license can be obtained from https://victoriametrics.com/products/enterprise/trial/ . This flag is available only in Enterprise binaries. The license key can be also passed via file specified by -licenseFile command-line flag
-license.forceOffline
Whether to enable offline verification for VictoriaMetrics Enterprise license key, which has been passed either via -license or via -licenseFile command-line flag. The issued license key must support offline verification feature. Contact info@victoriametrics.com if you need offline license verification. This flag is available only in Enterprise binaries
-licenseFile string
Path to file with license key for VictoriaMetrics Enterprise. See https://victoriametrics.com/products/enterprise/ . Trial Enterprise license can be obtained from https://victoriametrics.com/products/enterprise/trial/ . This flag is available only in Enterprise binaries. The license key can be also passed inline via -license command-line flag
-logNewSeries
Whether to log new series. This option is for debug purposes only. It can lead to performance issues when big number of new series are ingested into VictoriaMetrics
-loggerDisableTimestamps
Whether to disable writing timestamps in logs
-loggerErrorsPerSecondLimit int
Per-second limit on the number of ERROR messages. If more than the given number of errors are emitted per second, the remaining errors are suppressed. Zero values disable the rate limit
-loggerFormat string
Format for logs. Possible values: default, json (default "default")
-loggerJSONFields string
Allows renaming fields in JSON formatted logs. Example: "ts:timestamp,msg:message" renames "ts" to "timestamp" and "msg" to "message". Supported fields: ts, level, caller, msg
-loggerLevel string
Minimum level of errors to log. Possible values: INFO, WARN, ERROR, FATAL, PANIC (default "INFO")
-loggerMaxArgLen int
The maximum length of a single logged argument. Longer arguments are replaced with 'arg_start..arg_end', where 'arg_start' and 'arg_end' is prefix and suffix of the arg with the length not exceeding -loggerMaxArgLen / 2 (default 1000)
-loggerOutput string
Output for the logs. Supported values: stderr, stdout (default "stderr")
-loggerTimezone string
Timezone to use for timestamps in logs. Timezone must be a valid IANA Time Zone. For example: America/New_York, Europe/Berlin, Etc/GMT+3 or Local (default "UTC")
-loggerWarnsPerSecondLimit int
Per-second limit on the number of WARN messages. If more than the given number of warns are emitted per second, then the remaining warns are suppressed. Zero values disable the rate limit
-maxConcurrentInserts int
The maximum number of concurrent insert requests. Set higher value when clients send data over slow networks. Default value depends on the number of available CPU cores. It should work fine in most cases since it minimizes resource usage. See also -insert.maxQueueDuration (default 32)
-maxInsertRequestSize size
The maximum size in bytes of a single Prometheus remote_write API request
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 33554432)
-maxLabelValueLen int
The maximum length of label values in the accepted time series. Longer label values are truncated. In this case the vm_too_long_label_values_total metric at /metrics page is incremented (default 4096)
-maxLabelsPerTimeseries int
The maximum number of labels accepted per time series. Superfluous labels are dropped. In this case the vm_metrics_with_dropped_labels_total metric at /metrics page is incremented (default 30)
-memory.allowedBytes size
Allowed size of system memory VictoriaMetrics caches may occupy. This option overrides -memory.allowedPercent if set to a non-zero value. Too low a value may increase the cache miss rate usually resulting in higher CPU and disk IO usage. Too high a value may evict too much data from the OS page cache resulting in higher disk IO usage
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-memory.allowedPercent float
Allowed percent of system memory VictoriaMetrics caches may occupy. See also -memory.allowedBytes. Too low a value may increase cache miss rate usually resulting in higher CPU and disk IO usage. Too high a value may evict too much data from the OS page cache which will result in higher disk IO usage (default 60)
-metrics.exposeMetadata
Whether to expose TYPE and HELP metadata at the /metrics page, which is exposed at -httpListenAddr . The metadata may be needed when the /metrics page is consumed by systems, which require this information. For example, Managed Prometheus in Google Cloud - https://cloud.google.com/stackdriver/docs/managed-prometheus/troubleshooting#missing-metric-type
-metricsAuthKey value
Auth key for /metrics endpoint. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -metricsAuthKey=file:///abs/path/to/file or -metricsAuthKey=file://./relative/path/to/file . Flag value can be read from the given http/https url when using -metricsAuthKey=http://host/path or -metricsAuthKey=https://host/path
-mtls array
Whether to require valid client certificate for https requests to the corresponding -httpListenAddr . This flag works only if -tls flag is set. See also -mtlsCAFile . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/enterprise/
Supports array of values separated by comma or specified via multiple flags.
Empty values are set to false.
-mtlsCAFile array
Optional path to TLS Root CA for verifying client certificates at the corresponding -httpListenAddr when -mtls is enabled. By default the host system TLS Root CA is used for client certificate verification. This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-newrelic.maxInsertRequestSize size
The maximum size in bytes of a single NewRelic request to /newrelic/infra/v2/metrics/events/bulk
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 67108864)
-opentelemetry.usePrometheusNaming
Whether to convert metric names and labels into Prometheus-compatible format for the metrics ingested via OpenTelemetry protocol; see https://docs.victoriametrics.com/#sending-data-via-opentelemetry
-opentsdbHTTPListenAddr string
TCP address to listen for OpenTSDB HTTP put requests. Usually :4242 must be set. Doesn't work if empty. See also -opentsdbHTTPListenAddr.useProxyProtocol
-opentsdbHTTPListenAddr.useProxyProtocol
Whether to use proxy protocol for connections accepted at -opentsdbHTTPListenAddr . See https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt
-opentsdbListenAddr string
TCP and UDP address to listen for OpenTSDB metrics. Telnet put messages and HTTP /api/put messages are simultaneously served on TCP port. Usually :4242 must be set. Doesn't work if empty. See also -opentsdbListenAddr.useProxyProtocol
-opentsdbListenAddr.useProxyProtocol
Whether to use proxy protocol for connections accepted at -opentsdbListenAddr . See https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt
-opentsdbTrimTimestamp duration
Trim timestamps for OpenTSDB 'telnet put' data to this duration. Minimum practical duration is 1s. Higher duration (i.e. 1m) may be used for reducing disk space usage for timestamp data (default 1s)
-opentsdbhttp.maxInsertRequestSize size
The maximum size of OpenTSDB HTTP put request
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 33554432)
-opentsdbhttpTrimTimestamp duration
Trim timestamps for OpenTSDB HTTP data to this duration. Minimum practical duration is 1ms. Higher duration (i.e. 1s) may be used for reducing disk space usage for timestamp data (default 1ms)
-pprofAuthKey value
Auth key for /debug/pprof/* endpoints. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -pprofAuthKey=file:///abs/path/to/file or -pprofAuthKey=file://./relative/path/to/file . Flag value can be read from the given http/https url when using -pprofAuthKey=http://host/path or -pprofAuthKey=https://host/path
-precisionBits int
The number of precision bits to store per each value. Lower precision bits improves data compression at the cost of precision loss (default 64)
-prevCacheRemovalPercent float
Items in the previous caches are removed when the percent of requests it serves becomes lower than this value. Higher values reduce memory usage at the cost of higher CPU usage. See also -cacheExpireDuration (default 0.1)
-promscrape.azureSDCheckInterval duration
Interval for checking for changes in Azure. This works only if azure_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#azure_sd_configs for details (default 1m0s)
-promscrape.cluster.memberLabel string
If non-empty, then the label with this name and the -promscrape.cluster.memberNum value is added to all the scraped metrics. See https://docs.victoriametrics.com/vmagent/#scraping-big-number-of-targets for more info
-promscrape.cluster.memberNum string
The number of vmagent instance in the cluster of scrapers. It must be a unique value in the range 0 ... promscrape.cluster.membersCount-1 across scrapers in the cluster. Can be specified as pod name of Kubernetes StatefulSet - pod-name-Num, where Num is a numeric part of pod name. See also -promscrape.cluster.memberLabel . See https://docs.victoriametrics.com/vmagent/#scraping-big-number-of-targets for more info (default "0")
-promscrape.cluster.memberURLTemplate string
An optional template for URL to access vmagent instance with the given -promscrape.cluster.memberNum value. Every %d occurrence in the template is substituted with -promscrape.cluster.memberNum at urls to vmagent instances responsible for scraping the given target at /service-discovery page. For example -promscrape.cluster.memberURLTemplate='http://vmagent-%d:8429/targets'. See https://docs.victoriametrics.com/vmagent/#scraping-big-number-of-targets for more details
-promscrape.cluster.membersCount int
The number of members in a cluster of scrapers. Each member must have a unique -promscrape.cluster.memberNum in the range 0 ... promscrape.cluster.membersCount-1 . Each member then scrapes roughly 1/N of all the targets. By default, cluster scraping is disabled, i.e. a single scraper scrapes all the targets. See https://docs.victoriametrics.com/vmagent/#scraping-big-number-of-targets for more info (default 1)
-promscrape.cluster.name string
Optional name of the cluster. If multiple vmagent clusters scrape the same targets, then each cluster must have unique name in order to properly de-duplicate samples received from these clusters. See https://docs.victoriametrics.com/vmagent/#scraping-big-number-of-targets for more info
-promscrape.cluster.replicationFactor int
The number of members in the cluster, which scrape the same targets. If the replication factor is greater than 1, then the deduplication must be enabled at remote storage side. See https://docs.victoriametrics.com/vmagent/#scraping-big-number-of-targets for more info (default 1)
-promscrape.config string
Optional path to Prometheus config file with 'scrape_configs' section containing targets to scrape. The path can point to local file and to http url. See https://docs.victoriametrics.com/#how-to-scrape-prometheus-exporters-such-as-node-exporter for details
-promscrape.config.dryRun
Checks -promscrape.config file for errors and unsupported fields and then exits. Returns non-zero exit code on parsing errors and emits these errors to stderr. See also -promscrape.config.strictParse command-line flag. Pass -loggerLevel=ERROR if you don't need to see info messages in the output.
-promscrape.config.strictParse
Whether to deny unsupported fields in -promscrape.config . Set to false in order to silently skip unsupported fields (default true)
-promscrape.configCheckInterval duration
Interval for checking for changes in -promscrape.config file. By default, the checking is disabled. See how to reload -promscrape.config file at https://docs.victoriametrics.com/vmagent/#configuration-update
-promscrape.consul.waitTime duration
Wait time used by Consul service discovery. Default value is used if not set
-promscrape.consulSDCheckInterval duration
Interval for checking for changes in Consul. This works only if consul_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#consul_sd_configs for details (default 30s)
-promscrape.consulagentSDCheckInterval duration
Interval for checking for changes in Consul Agent. This works only if consulagent_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#consulagent_sd_configs for details (default 30s)
-promscrape.digitaloceanSDCheckInterval duration
Interval for checking for changes in digital ocean. This works only if digitalocean_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#digitalocean_sd_configs for details (default 1m0s)
-promscrape.disableCompression
Whether to disable sending 'Accept-Encoding: gzip' request headers to all the scrape targets. This may reduce CPU usage on scrape targets at the cost of higher network bandwidth utilization. It is possible to set 'disable_compression: true' individually per each 'scrape_config' section in '-promscrape.config' for fine-grained control
-promscrape.disableKeepAlive
Whether to disable HTTP keep-alive connections when scraping all the targets. This may be useful when targets has no support for HTTP keep-alive connection. It is possible to set 'disable_keepalive: true' individually per each 'scrape_config' section in '-promscrape.config' for fine-grained control. Note that disabling HTTP keep-alive may increase load on both vmagent and scrape targets
-promscrape.discovery.concurrency int
The maximum number of concurrent requests to Prometheus autodiscovery API (Consul, Kubernetes, etc.) (default 100)
-promscrape.discovery.concurrentWaitTime duration
The maximum duration for waiting to perform API requests if more than -promscrape.discovery.concurrency requests are simultaneously performed (default 1m0s)
-promscrape.dnsSDCheckInterval duration
Interval for checking for changes in dns. This works only if dns_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#dns_sd_configs for details (default 30s)
-promscrape.dockerSDCheckInterval duration
Interval for checking for changes in docker. This works only if docker_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#docker_sd_configs for details (default 30s)
-promscrape.dockerswarmSDCheckInterval duration
Interval for checking for changes in dockerswarm. This works only if dockerswarm_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#dockerswarm_sd_configs for details (default 30s)
-promscrape.dropOriginalLabels
Whether to drop original labels for scrape targets at /targets and /api/v1/targets pages. This may be needed for reducing memory usage when original labels for big number of scrape targets occupy big amounts of memory. Note that this reduces debuggability for improper per-target relabeling configs
-promscrape.ec2SDCheckInterval duration
Interval for checking for changes in ec2. This works only if ec2_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#ec2_sd_configs for details (default 1m0s)
-promscrape.eurekaSDCheckInterval duration
Interval for checking for changes in eureka. This works only if eureka_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#eureka_sd_configs for details (default 30s)
-promscrape.fileSDCheckInterval duration
Interval for checking for changes in 'file_sd_config'. See https://docs.victoriametrics.com/sd_configs/#file_sd_configs for details (default 1m0s)
-promscrape.gceSDCheckInterval duration
Interval for checking for changes in gce. This works only if gce_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#gce_sd_configs for details (default 1m0s)
-promscrape.hetznerSDCheckInterval duration
Interval for checking for changes in Hetzner API. This works only if hetzner_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#hetzner_sd_configs for details (default 1m0s)
-promscrape.httpSDCheckInterval duration
Interval for checking for changes in http endpoint service discovery. This works only if http_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#http_sd_configs for details (default 1m0s)
-promscrape.kubernetes.apiServerTimeout duration
How frequently to reload the full state from Kubernetes API server (default 30m0s)
-promscrape.kubernetes.attachNodeMetadataAll
Whether to set attach_metadata.node=true for all the kubernetes_sd_configs at -promscrape.config . It is possible to set attach_metadata.node=false individually per each kubernetes_sd_configs . See https://docs.victoriametrics.com/sd_configs/#kubernetes_sd_configs
-promscrape.kubernetes.useHTTP2Client
Whether to use HTTP/2 client for connection to Kubernetes API server. This may reduce amount of concurrent connections to API server when watching for a big number of Kubernetes objects.
-promscrape.kubernetesSDCheckInterval duration
Interval for checking for changes in Kubernetes API server. This works only if kubernetes_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#kubernetes_sd_configs for details (default 30s)
-promscrape.kumaSDCheckInterval duration
Interval for checking for changes in kuma service discovery. This works only if kuma_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#kuma_sd_configs for details (default 30s)
-promscrape.maxDroppedTargets int
The maximum number of droppedTargets to show at /api/v1/targets page. Increase this value if your setup drops more scrape targets during relabeling and you need investigating labels for all the dropped targets. Note that the increased number of tracked dropped targets may result in increased memory usage (default 10000)
-promscrape.maxResponseHeadersSize size
The maximum size of http response headers from Prometheus scrape targets
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 4096)
-promscrape.maxScrapeSize size
The maximum size of scrape response in bytes to process from Prometheus targets. Bigger responses are rejected
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 16777216)
-promscrape.minResponseSizeForStreamParse size
The minimum target response size for automatic switching to stream parsing mode, which can reduce memory usage. See https://docs.victoriametrics.com/vmagent/#stream-parsing-mode
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 1000000)
-promscrape.noStaleMarkers
Whether to disable sending Prometheus stale markers for metrics when scrape target disappears. This option may reduce memory usage if stale markers aren't needed for your setup. This option also disables populating the scrape_series_added metric. See https://prometheus.io/docs/concepts/jobs_instances/#automatically-generated-labels-and-time-series
-promscrape.nomad.waitTime duration
Wait time used by Nomad service discovery. Default value is used if not set
-promscrape.nomadSDCheckInterval duration
Interval for checking for changes in Nomad. This works only if nomad_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#nomad_sd_configs for details (default 30s)
-promscrape.openstackSDCheckInterval duration
Interval for checking for changes in openstack API server. This works only if openstack_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#openstack_sd_configs for details (default 30s)
-promscrape.ovhcloudSDCheckInterval duration
Interval for checking for changes in OVH Cloud VPS and dedicated server. This works only if ovhcloud_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#ovhcloud_sd_configs for details (default 30s)
-promscrape.puppetdbSDCheckInterval duration
Interval for checking for changes in PuppetDB API. This works only if puppetdb_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#puppetdb_sd_configs for details (default 30s)
-promscrape.seriesLimitPerTarget int
Optional limit on the number of unique time series a single scrape target can expose. See https://docs.victoriametrics.com/vmagent/#cardinality-limiter for more info
-promscrape.streamParse
Whether to enable stream parsing for metrics obtained from scrape targets. This may be useful for reducing memory usage when millions of metrics are exposed per each scrape target. It is possible to set 'stream_parse: true' individually per each 'scrape_config' section in '-promscrape.config' for fine-grained control
-promscrape.suppressDuplicateScrapeTargetErrors
Whether to suppress 'duplicate scrape target' errors; see https://docs.victoriametrics.com/vmagent/#troubleshooting for details
-promscrape.suppressScrapeErrors
Whether to suppress scrape errors logging. The last error for each target is always available at '/targets' page even if scrape errors logging is suppressed. See also -promscrape.suppressScrapeErrorsDelay
-promscrape.suppressScrapeErrorsDelay duration
The delay for suppressing repeated scrape errors logging per each scrape targets. This may be used for reducing the number of log lines related to scrape errors. See also -promscrape.suppressScrapeErrors
-promscrape.yandexcloudSDCheckInterval duration
Interval for checking for changes in Yandex Cloud API. This works only if yandexcloud_sd_configs is configured in '-promscrape.config' file. See https://docs.victoriametrics.com/sd_configs/#yandexcloud_sd_configs for details (default 30s)
-pushmetrics.disableCompression
Whether to disable request body compression when pushing metrics to every -pushmetrics.url
-pushmetrics.extraLabel array
Optional labels to add to metrics pushed to every -pushmetrics.url . For example, -pushmetrics.extraLabel='instance="foo"' adds instance="foo" label to all the metrics pushed to every -pushmetrics.url
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-pushmetrics.header array
Optional HTTP request header to send to every -pushmetrics.url . For example, -pushmetrics.header='Authorization: Basic foobar' adds 'Authorization: Basic foobar' header to every request to every -pushmetrics.url
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-pushmetrics.interval duration
Interval for pushing metrics to every -pushmetrics.url (default 10s)
-pushmetrics.url array
Optional URL to push metrics exposed at /metrics page. See https://docs.victoriametrics.com/#push-metrics . By default, metrics exposed at /metrics page aren't pushed to any remote storage
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-relabelConfig string
Optional path to a file with relabeling rules, which are applied to all the ingested metrics. The path can point either to local file or to http url. See https://docs.victoriametrics.com/#relabeling for details. The config is reloaded on SIGHUP signal
-reloadAuthKey value
Auth key for /-/reload http endpoint. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -reloadAuthKey=file:///abs/path/to/file or -reloadAuthKey=file://./relative/path/to/file . Flag value can be read from the given http/https url when using -reloadAuthKey=http://host/path or -reloadAuthKey=https://host/path
-retentionFilter array
Retention filter in the format 'filter:retention'. For example, '{env="dev"}:3d' configures the retention for time series with env="dev" label to 3 days. See https://docs.victoriametrics.com/#retention-filters for details. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-retentionPeriod value
Data with timestamps outside the retentionPeriod is automatically deleted. The minimum retentionPeriod is 24h or 1d. See also -retentionFilter
The following optional suffixes are supported: s (second), h (hour), d (day), w (week), y (year). If suffix isn't set, then the duration is counted in months (default 1)
-retentionTimezoneOffset duration
The offset for performing indexdb rotation. If set to 0, then the indexdb rotation is performed at 4am UTC time per each -retentionPeriod. If set to 2h, then the indexdb rotation is performed at 4am EET time (the timezone with +2h offset)
-search.cacheTimestampOffset duration
The maximum duration since the current time for response data, which is always queried from the original raw data, without using the response cache. Increase this value if you see gaps in responses due to time synchronization issues between VictoriaMetrics and data sources. See also -search.disableAutoCacheReset (default 5m0s)
-search.disableAutoCacheReset
Whether to disable automatic response cache reset if a sample with timestamp outside -search.cacheTimestampOffset is inserted into VictoriaMetrics
-search.disableCache
Whether to disable response caching. This may be useful when ingesting historical data. See https://docs.victoriametrics.com/#backfilling . See also -search.resetRollupResultCacheOnStartup
-search.disableImplicitConversion
Whether to return an error for queries that rely on implicit subquery conversions, see https://docs.victoriametrics.com/metricsql/#subqueries for details. See also -search.logImplicitConversion
-search.graphiteMaxPointsPerSeries int
The maximum number of points per series Graphite render API can return (default 1000000)
-search.graphiteStorageStep duration
The interval between datapoints stored in the database. It is used at Graphite Render API handler for normalizing the interval between datapoints in case it isn't normalized. It can be overridden by sending 'storage_step' query arg to /render API or by sending the desired interval via 'Storage-Step' http header during querying /render API (default 10s)
-search.ignoreExtraFiltersAtLabelsAPI
Whether to ignore match[], extra_filters[] and extra_label query args at /api/v1/labels and /api/v1/label/.../values . This may be useful for decreasing load on VictoriaMetrics when extra filters match too many time series. The downside is that superfluous labels or series could be returned, which do not match the extra filters. See also -search.maxLabelsAPISeries and -search.maxLabelsAPIDuration
-search.latencyOffset duration
The time when data points become visible in query results after the collection. It can be overridden on per-query basis via latency_offset arg. Too small value can result in incomplete last points for query results (default 30s)
-search.logImplicitConversion
Whether to log queries with implicit subquery conversions, see https://docs.victoriametrics.com/metricsql/#subqueries for details. Such conversion can be disabled using -search.disableImplicitConversion
-search.logQueryMemoryUsage size
Log query and increment vm_memory_intensive_queries_total metric each time the query requires more memory than specified by this flag. This may help detecting and optimizing heavy queries. Query logging is disabled by default. See also -search.logSlowQueryDuration and -search.maxMemoryPerQuery
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-search.logSlowQueryDuration duration
Log queries with execution time exceeding this value. Zero disables slow query logging. See also -search.logQueryMemoryUsage (default 5s)
-search.maxConcurrentRequests int
The maximum number of concurrent search requests. It shouldn't be high, since a single request can saturate all the CPU cores, while many concurrently executed requests may require high amounts of memory. See also -search.maxQueueDuration and -search.maxMemoryPerQuery (default 16)
-search.maxExportDuration duration
The maximum duration for /api/v1/export call (default 720h0m0s)
-search.maxExportSeries int
The maximum number of time series, which can be returned from /api/v1/export* APIs. This option allows limiting memory usage (default 10000000)
-search.maxFederateSeries int
The maximum number of time series, which can be returned from /federate. This option allows limiting memory usage (default 1000000)
-search.maxGraphiteSeries int
The maximum number of time series, which can be scanned during queries to Graphite Render API. See https://docs.victoriametrics.com/#graphite-render-api-usage (default 300000)
-search.maxGraphiteTagKeys int
The maximum number of tag keys returned from Graphite API, which returns tags. See https://docs.victoriametrics.com/#graphite-tags-api-usage (default 100000)
-search.maxGraphiteTagValues int
The maximum number of tag values returned from Graphite API, which returns tag values. See https://docs.victoriametrics.com/#graphite-tags-api-usage (default 100000)
-search.maxLabelsAPIDuration duration
The maximum duration for /api/v1/labels, /api/v1/label/.../values and /api/v1/series requests. See also -search.maxLabelsAPISeries and -search.ignoreExtraFiltersAtLabelsAPI (default 5s)
-search.maxLabelsAPISeries int
The maximum number of time series, which could be scanned when searching for the matching time series at /api/v1/labels and /api/v1/label/.../values. This option allows limiting memory usage and CPU usage. See also -search.maxLabelsAPIDuration, -search.maxTagKeys, -search.maxTagValues and -search.ignoreExtraFiltersAtLabelsAPI (default 1000000)
-search.maxLookback duration
Synonym to -search.lookback-delta from Prometheus. The value is dynamically detected from interval between time series datapoints if not set. It can be overridden on per-query basis via max_lookback arg. See also '-search.maxStalenessInterval' flag, which has the same meaning due to historical reasons
-search.maxMemoryPerQuery size
The maximum amounts of memory a single query may consume. Queries requiring more memory are rejected. The total memory limit for concurrently executed queries can be estimated as -search.maxMemoryPerQuery multiplied by -search.maxConcurrentRequests . See also -search.logQueryMemoryUsage
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-search.maxPointsPerTimeseries int
The maximum points per a single timeseries returned from /api/v1/query_range. This option doesn't limit the number of scanned raw samples in the database. The main purpose of this option is to limit the number of per-series points returned to graphing UI such as VMUI or Grafana. There is no sense in setting this limit to values bigger than the horizontal resolution of the graph. See also -search.maxResponseSeries (default 30000)
-search.maxPointsSubqueryPerTimeseries int
The maximum number of points per series, which can be generated by subquery. See https://valyala.medium.com/prometheus-subqueries-in-victoriametrics-9b1492b720b3 (default 100000)
-search.maxQueryDuration duration
The maximum duration for query execution. It can be overridden to a smaller value on a per-query basis via 'timeout' query arg (default 30s)
-search.maxQueryLen size
The maximum search query length in bytes
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 16384)
-search.maxQueueDuration duration
The maximum time the request waits for execution when -search.maxConcurrentRequests limit is reached; see also -search.maxQueryDuration (default 10s)
-search.maxResponseSeries int
The maximum number of time series which can be returned from /api/v1/query and /api/v1/query_range . The limit is disabled if it equals to 0. See also -search.maxPointsPerTimeseries and -search.maxUniqueTimeseries
-search.maxSamplesPerQuery int
The maximum number of raw samples a single query can process across all time series. This protects from heavy queries, which select unexpectedly high number of raw samples. See also -search.maxSamplesPerSeries (default 1000000000)
-search.maxSamplesPerSeries int
The maximum number of raw samples a single query can scan per each time series. This option allows limiting memory usage (default 30000000)
-search.maxSeries int
The maximum number of time series, which can be returned from /api/v1/series. This option allows limiting memory usage (default 30000)
-search.maxSeriesPerAggrFunc int
The maximum number of time series an aggregate MetricsQL function can generate (default 1000000)
-search.maxStalenessInterval duration
The maximum interval for staleness calculations. By default, it is automatically calculated from the median interval between samples. This flag could be useful for tuning Prometheus data model closer to Influx-style data model. See https://prometheus.io/docs/prometheus/latest/querying/basics/#staleness for details. See also '-search.setLookbackToStep' flag
-search.maxStatusRequestDuration duration
The maximum duration for /api/v1/status/* requests (default 5m0s)
-search.maxStepForPointsAdjustment duration
The maximum step when /api/v1/query_range handler adjusts points with timestamps closer than -search.latencyOffset to the current time. The adjustment is needed because such points may contain incomplete data (default 1m0s)
-search.maxTSDBStatusSeries int
The maximum number of time series, which can be processed during the call to /api/v1/status/tsdb. This option allows limiting memory usage (default 10000000)
-search.maxTagKeys int
The maximum number of tag keys returned from /api/v1/labels . See also -search.maxLabelsAPISeries and -search.maxLabelsAPIDuration (default 100000)
-search.maxTagValueSuffixesPerSearch int
The maximum number of tag value suffixes returned from /metrics/find (default 100000)
-search.maxTagValues int
The maximum number of tag values returned from /api/v1/label/<label_name>/values . See also -search.maxLabelsAPISeries and -search.maxLabelsAPIDuration (default 100000)
-search.maxUniqueTimeseries int
The maximum number of unique time series, which can be selected during /api/v1/query and /api/v1/query_range queries. This option allows limiting memory usage. When set to zero, the limit is automatically calculated based on -search.maxConcurrentRequests (inversely proportional) and memory available to the process (proportional). (default 0)
-search.maxWorkersPerQuery int
The maximum number of CPU cores a single query can use. The default value should work good for most cases. The flag can be set to lower values for improving performance of big number of concurrently executed queries. The flag can be set to bigger values for improving performance of heavy queries, which scan big number of time series (>10K) and/or big number of samples (>100M). There is no sense in setting this flag to values bigger than the number of CPU cores available on the system (default 16)
-search.minStalenessInterval duration
The minimum interval for staleness calculations. This flag could be useful for removing gaps on graphs generated from time series with irregular intervals between samples. See also '-search.maxStalenessInterval'
-search.minWindowForInstantRollupOptimization value
Enable cache-based optimization for repeated queries to /api/v1/query (aka instant queries), which contain rollup functions with lookbehind window exceeding the given value
The following optional suffixes are supported: s (second), h (hour), d (day), w (week), y (year). If suffix isn't set, then the duration is counted in months (default 3h)
-search.noStaleMarkers
Set this flag to true if the database doesn't contain Prometheus stale markers, so there is no need in spending additional CPU time on its handling. Staleness markers may exist only in data obtained from Prometheus scrape targets
-search.queryStats.lastQueriesCount int
Query stats for /api/v1/status/top_queries is tracked on this number of last queries. Zero value disables query stats tracking (default 20000)
-search.queryStats.minQueryDuration duration
The minimum duration for queries to track in query stats at /api/v1/status/top_queries. Queries with lower duration are ignored in query stats (default 1ms)
-search.resetCacheAuthKey value
Optional authKey for resetting rollup cache via /internal/resetRollupResultCache call
Flag value can be read from the given file when using -search.resetCacheAuthKey=file:///abs/path/to/file or -search.resetCacheAuthKey=file://./relative/path/to/file . Flag value can be read from the given http/https url when using -search.resetCacheAuthKey=http://host/path or -search.resetCacheAuthKey=https://host/path
-search.resetRollupResultCacheOnStartup
Whether to reset rollup result cache on startup. See https://docs.victoriametrics.com/#rollup-result-cache . See also -search.disableCache
-search.setLookbackToStep
Whether to fix lookback interval to 'step' query arg value. If set to true, the query model becomes closer to InfluxDB data model. If set to true, then -search.maxLookback and -search.maxStalenessInterval are ignored
-search.treatDotsAsIsInRegexps
Whether to treat dots as is in regexp label filters used in queries. For example, foo{bar=~"a.b.c"} will be automatically converted to foo{bar=~"a\\.b\\.c"}, i.e. all the dots in regexp filters will be automatically escaped in order to match only dot char instead of matching any char. Dots in ".+", ".*" and ".{n}" regexps aren't escaped. This option is DEPRECATED in favor of {__graphite__="a.*.c"} syntax for selecting metrics matching the given Graphite metrics filter
-selfScrapeInstance string
Value for 'instance' label, which is added to self-scraped metrics (default "self")
-selfScrapeInterval duration
Interval for self-scraping own metrics at /metrics page
-selfScrapeJob string
Value for 'job' label, which is added to self-scraped metrics (default "victoria-metrics")
-smallMergeConcurrency int
Deprecated: this flag does nothing
-snapshotAuthKey value
authKey, which must be passed in query string to /snapshot* pages
Flag value can be read from the given file when using -snapshotAuthKey=file:///abs/path/to/file or -snapshotAuthKey=file://./relative/path/to/file . Flag value can be read from the given http/https url when using -snapshotAuthKey=http://host/path or -snapshotAuthKey=https://host/path
-snapshotCreateTimeout duration
Deprecated: this flag does nothing
-snapshotsMaxAge value
Automatically delete snapshots older than -snapshotsMaxAge if it is set to non-zero duration. Make sure that backup process has enough time to finish the backup before the corresponding snapshot is automatically deleted
The following optional suffixes are supported: s (second), h (hour), d (day), w (week), y (year). If suffix isn't set, then the duration is counted in months (default 0)
-sortLabels
Whether to sort labels for incoming samples before writing them to storage. This may be needed for reducing memory usage at storage when the order of labels in incoming samples is random. For example, if m{k1="v1",k2="v2"} may be sent as m{k2="v2",k1="v1"}. Enabled sorting for labels can slow down ingestion performance a bit
-storage.cacheSizeIndexDBDataBlocks size
Overrides max size for indexdb/dataBlocks cache. See https://docs.victoriametrics.com/single-server-victoriametrics/#cache-tuning
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-storage.cacheSizeIndexDBIndexBlocks size
Overrides max size for indexdb/indexBlocks cache. See https://docs.victoriametrics.com/single-server-victoriametrics/#cache-tuning
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-storage.cacheSizeIndexDBTagFilters size
Overrides max size for indexdb/tagFiltersToMetricIDs cache. See https://docs.victoriametrics.com/single-server-victoriametrics/#cache-tuning
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-storage.cacheSizeStorageTSID size
Overrides max size for storage/tsid cache. See https://docs.victoriametrics.com/single-server-victoriametrics/#cache-tuning
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-storage.maxDailySeries int
The maximum number of unique series can be added to the storage during the last 24 hours. Excess series are logged and dropped. This can be useful for limiting series churn rate. See https://docs.victoriametrics.com/#cardinality-limiter . See also -storage.maxHourlySeries
-storage.maxHourlySeries int
The maximum number of unique series can be added to the storage during the last hour. Excess series are logged and dropped. This can be useful for limiting series cardinality. See https://docs.victoriametrics.com/#cardinality-limiter . See also -storage.maxDailySeries
-storage.minFreeDiskSpaceBytes size
The minimum free disk space at -storageDataPath after which the storage stops accepting new data
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 10000000)
-storageDataPath string
Path to storage data (default "victoria-metrics-data")
-streamAggr.config string
Optional path to file with stream aggregation config. See https://docs.victoriametrics.com/stream-aggregation/ . See also -streamAggr.keepInput, -streamAggr.dropInput and -streamAggr.dedupInterval
-streamAggr.dedupInterval duration
Input samples are de-duplicated with this interval before optional aggregation with -streamAggr.config . See also -streamAggr.dropInputLabels and -dedup.minScrapeInterval and https://docs.victoriametrics.com/stream-aggregation/#deduplication
-streamAggr.dropInput
Whether to drop all the input samples after the aggregation with -streamAggr.config. By default, only aggregated samples are dropped, while the remaining samples are stored in the database. See also -streamAggr.keepInput and https://docs.victoriametrics.com/stream-aggregation/
-streamAggr.dropInputLabels array
An optional list of labels to drop from samples before stream de-duplication and aggregation . See https://docs.victoriametrics.com/stream-aggregation/#dropping-unneeded-labels
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-streamAggr.ignoreFirstIntervals int
Number of aggregation intervals to skip after the start. Increase this value if you observe incorrect aggregation results after restarts. It could be caused by receiving unordered delayed data from clients pushing data into the database. See https://docs.victoriametrics.com/stream-aggregation/#ignore-aggregation-intervals-on-start
-streamAggr.ignoreOldSamples
Whether to ignore input samples with old timestamps outside the current aggregation interval. See https://docs.victoriametrics.com/stream-aggregation/#ignoring-old-samples
-streamAggr.keepInput
Whether to keep all the input samples after the aggregation with -streamAggr.config. By default, only aggregated samples are dropped, while the remaining samples are stored in the database. See also -streamAggr.dropInput and https://docs.victoriametrics.com/stream-aggregation/
-tls array
Whether to enable TLS for incoming HTTP requests at the given -httpListenAddr (aka https). -tlsCertFile and -tlsKeyFile must be set if -tls is set. See also -mtls
Supports array of values separated by comma or specified via multiple flags.
Empty values are set to false.
-tlsAutocertCacheDir string
Directory to store TLS certificates issued via Let's Encrypt. Certificates are lost on restarts if this flag isn't set. This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/enterprise/
-tlsAutocertEmail string
Contact email for the issued Let's Encrypt TLS certificates. See also -tlsAutocertHosts and -tlsAutocertCacheDir .This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/enterprise/
-tlsAutocertHosts array
Optional hostnames for automatic issuing of Let's Encrypt TLS certificates. These hostnames must be reachable at -httpListenAddr . The -httpListenAddr must listen tcp port 443 . The -tlsAutocertHosts overrides -tlsCertFile and -tlsKeyFile . See also -tlsAutocertEmail and -tlsAutocertCacheDir . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsCertFile array
Path to file with TLS certificate for the corresponding -httpListenAddr if -tls is set. Prefer ECDSA certs instead of RSA certs as RSA certs are slower. The provided certificate file is automatically re-read every second, so it can be dynamically updated. See also -tlsAutocertHosts
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsCipherSuites array
Optional list of TLS cipher suites for incoming requests over HTTPS if -tls is set. See the list of supported cipher suites at https://pkg.go.dev/crypto/tls#pkg-constants
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsKeyFile array
Path to file with TLS key for the corresponding -httpListenAddr if -tls is set. The provided key file is automatically re-read every second, so it can be dynamically updated. See also -tlsAutocertHosts
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsMinVersion array
Optional minimum TLS version to use for the corresponding -httpListenAddr if -tls is set. Supported values: TLS10, TLS11, TLS12, TLS13
Supports an array of values separated by comma or specified via multiple flags.
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-usePromCompatibleNaming
Whether to replace characters unsupported by Prometheus with underscores in the ingested metric names and label names. For example, foo.bar{a.b='c'} is transformed into foo_bar{a_b='c'} during data ingestion if this flag is set. See https://prometheus.io/docs/concepts/data_model/#metric-names-and-labels
-version
Show VictoriaMetrics version
-vmalert.proxyURL string
Optional URL for proxying requests to vmalert. For example, if -vmalert.proxyURL=http://vmalert:8880 , then alerting API requests such as /api/v1/rules from Grafana will be proxied to http://vmalert:8880/api/v1/rules
-vmui.customDashboardsPath string
Optional path to vmui dashboards. See https://github.com/VictoriaMetrics/VictoriaMetrics/tree/master/app/vmui/packages/vmui/public/dashboards
-vmui.defaultTimezone string
The default timezone to be used in vmui. Timezone must be a valid IANA Time Zone. For example: America/New_York, Europe/Berlin, Etc/GMT+3 or Local