* update link to book a demo for AD & RCA * fix invalid refs in components/model * - fix staging -> prod links - replace capitalized FAQ headers - change the section order on main page - replace :latest tag with current stable
12 KiB
| sort | weight | title | menu | aliases | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 11 | 11 | vmanomaly |
|
|
vmanomaly
vmanomaly is a part of enterprise package. You need to request a free trial license for evaluation.
Please head to to Anomaly Detection section to find out more.
About
VictoriaMetrics Anomaly Detection (or shortly, vmanomaly) is a service that continuously scans VictoriaMetrics time
series and detects unexpected changes within data patterns in real-time. It does so by utilizing
user-configurable machine learning models.
It periodically queries user-specified metrics, computes an “anomaly score” for them, based on how well they fit a predicted distribution, taking into account periodical data patterns with trends, and pushes back the computed “anomaly score” to VictoriaMetrics. Then, users can enable alerting rules based on the “anomaly score”.
Compared to classical alerting rules, anomaly detection is more “hands-off” i.e. it allows users to avoid setting up manual alerting rules set up and catching anomalies that were not expected to happen. In other words, by setting up alerting rules, a user must know what to look for, ahead of time, while anomaly detection looks for any deviations from past behavior.
In addition to that, setting up alerting rules manually has been proven to be tedious and error-prone, while anomaly detection can be easier to set up, and use the same model for different metrics.
How?
VictoriaMetrics Anomaly Detection service (vmanomaly) allows you to apply several built-in anomaly detection algorithms. You can also plug in your own detection models, code doesn’t make any distinction between built-in models or external ones.
All the service parameters (model, schedule, input-output) are defined in a config file.
Single config file supports only one model, but it’s totally OK to run multiple vmanomaly processes in parallel, each using its own config.
Models
Currently, vmanomaly ships with a set of built-in models:
For a detailed description, see model section
-
(useful for testing)
Simplistic model, that detects outliers as all the points that lie farther than a certain amount from time-series mean (straight line). Keeps only two model parameters internally:
meanandstd(standard deviation). -
(simplest in configuration, recommended for getting starting)
Uses Facebook Prophet for forecasting. The anomaly score is computed of how close the actual time series values follow the forecasted values (yhat), and whether it’s within forecasted bounds (yhat_lower, yhat_upper). The anomaly score reaches 1.0 if the actual data values are equal to yhat_lower or yhat_upper. The anomaly score is above 1.0 if the actual data values are outside the yhat_lower/yhat_upper bounds.
-
Very popular forecasting algorithm. See statsmodels.org documentation for Holt-Winters exponential smoothing.
-
Extracts three components: season, trend, and residual, that can be plotted individually for easier debugging. Uses LOESS (locally estimated scatterplot smoothing). See statsmodels.org documentation for LOESS STD.
-
Commonly used forecasting model. See statsmodels.org documentation for ARIMA.
-
A simple moving window of quantiles. Easy to use, easy to understand, but not as powerful as other models.
-
Detects anomalies using binary trees. It works for both univariate and multivariate data. Be aware of the curse of dimensionality in the case of multivariate data - we advise against using a single model when handling multiple time series if the number of these series significantly exceeds their average length (# of data points).
The algorithm has a linear time complexity and a low memory requirement, which works well with high-volume data. See scikit-learn.org documentation for Isolation Forest.
-
MAD (Median Absolute Deviation)
A robust method for anomaly detection that is less sensitive to outliers in data compared to standard deviation-based models. It considers a point as an anomaly if the absolute deviation from the median is significantly large.
Examples
For example, here’s how Prophet predictions could look like on a real-data example
(Prophet auto-detected seasonality interval):
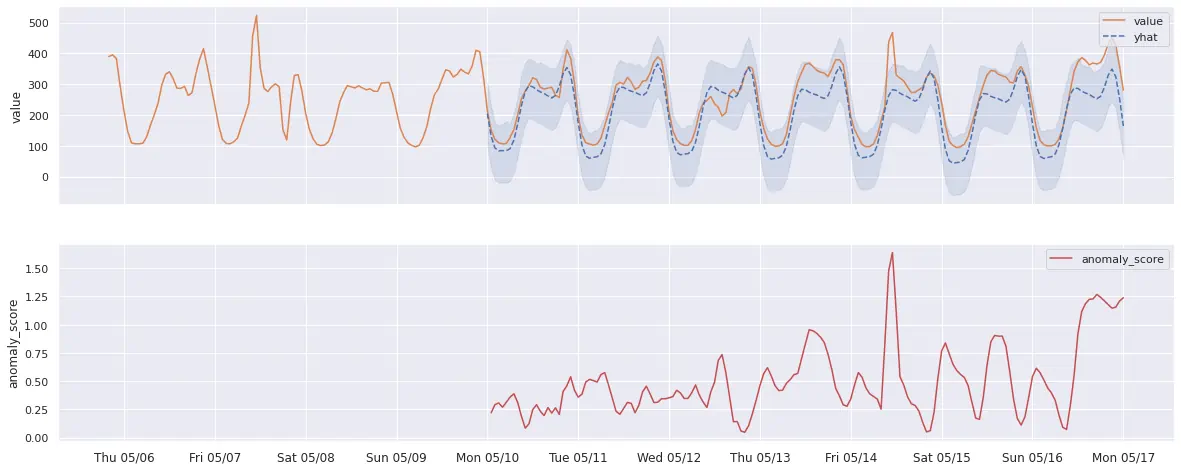
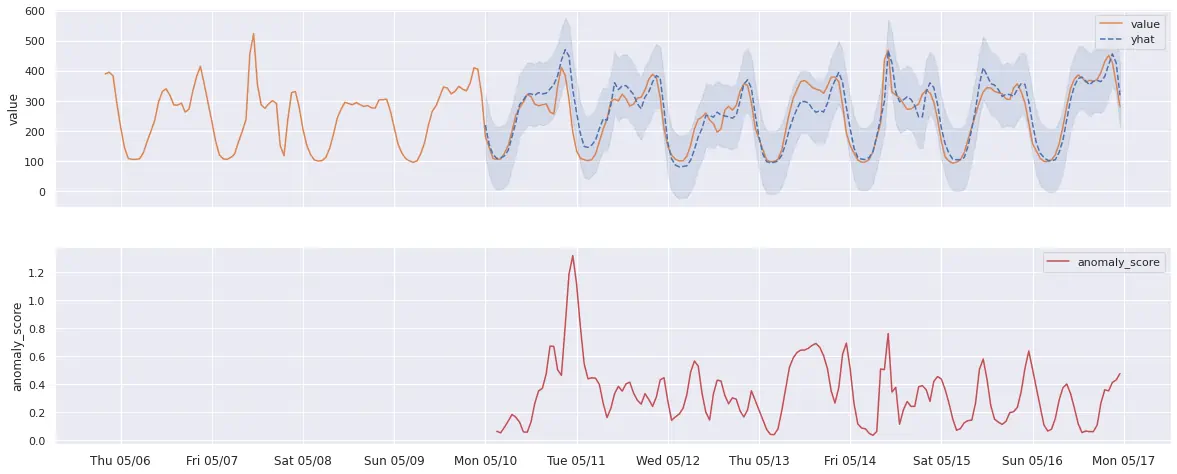
And here’s what Holt-Winters predictions real-world data could look like (seasonality manually set to 1 week). Notice that it predicts anomalies in different places than Prophet because the model noticed there are usually spikes on Friday morning, so it accounted for that:
Process
Upon starting, vmanomaly queries the initial range of data, and trains its model (“fit” by convention).
Then, reads new data from VictoriaMetrics, according to schedule, and invokes its model to compute “anomaly score” for each data point. The anomaly score ranges from 0 to positive infinity. Values less than 1.0 are considered “not an anomaly”, values greater or equal than 1.0 are considered “anomalous”, with greater values corresponding to larger anomaly. Then, vmanomaly pushes the metric to vminsert (under the user-configured metric name, optionally preserving labels).
Usage
Starting from v1.5.0, vmanomaly requires a license key to run. You can obtain a trial license key here.
Config file
There are 4 required sections in config file:
scheduler- defines how often to run and make inferences, as well as what timerange to use to train the model.model- specific model parameters and configurations,reader- how to read data and where it is locatedwriter- where and how to write the generated output.
monitoring - defines how to monitor work of vmanomaly service. This config section is optional.
For a detailed description, see config sections
Config example
Here is an example of config file that will run FB Prophet model, that will be retrained every 2 hours on 14 days of previous data. It will generate inference (including anomaly_score metric) every 1 minute.
You need to put your datasource urls to use it:
scheduler:
infer_every: "1m"
fit_every: "2h"
fit_window: "14d"
model:
class: "model.prophet.ProphetModel"
args:
interval_width: 0.98
reader:
datasource_url: [YOUR_DATASOURCE_URL] #Example: "http://victoriametrics:8428/"
queries:
cache: "sum(rate(vm_cache_entries))"
writer:
datasource_url: [YOUR_DATASOURCE_URL] # Example: "http://victoriametrics:8428/"
Monitoring
vmanomaly can be monitored by using push or pull approach. It can push metrics to VictoriaMetrics or expose metrics in Prometheus exposition format.
For a detailed description, see monitoring section
Push approach
vmanomaly can push metrics to VictoriaMetrics single-node or cluster version.
In order to enable push approach, specify push section in config file:
monitoring:
push:
url: [YOUR_DATASOURCE_URL] #Example: "http://victoriametrics:8428/"
extra_labels:
job: "vmanomaly-push"
Pull approach
vmanomaly can export internal metrics in Prometheus exposition format at /metrics page.
These metrics can be scraped via vmagent or Prometheus.
In order to enable pull approach, specify pull section in config file:
monitoring:
pull:
enable: true
port: 8080
This will expose metrics at http://0.0.0.0:8080/metrics page.
Run vmanomaly Docker Container
To use vmanomaly you need to pull docker image:
docker pull us-docker.pkg.dev/victoriametrics-test/public/vmanomaly-trial:1.7.2
Note: please check what is latest release in CHANGELOG
You can put a tag on it for your convinience:
docker image tag us-docker.pkg.dev/victoriametrics-test/public/vmanomaly-trial vmanomaly
Here is an example of how to run vmanomaly docker container with license file:
docker run -it --net [YOUR_NETWORK] \
-v [YOUR_LICENSE_FILE_PATH]:/license.txt \
-v [YOUR_CONFIG_FILE_PATH]:/config.yml \
vmanomaly /config.yml \
--license-file=/license.txt
Licensing
The license key can be passed via the following command-line flags:
--license LICENSE See https://victoriametrics.com/products/enterprise/
for trial license
--license-file LICENSE_FILE
See https://victoriametrics.com/products/enterprise/
for trial license
--license-verify-offline {true,false}
Force offline verification of license code. License is
verified online by default. This flag runs license
verification offline.
In order to make it easier to monitor the license expiration date, the following metrics are exposed(see Monitoring section for details on how to scrape them):
# HELP vm_license_expires_at When the license expires as a Unix timestamp in seconds
# TYPE vm_license_expires_at gauge
vm_license_expires_at 1.6963776e+09
# HELP vm_license_expires_in_seconds Amount of seconds until the license expires
# TYPE vm_license_expires_in_seconds gauge
vm_license_expires_in_seconds 4.886608e+06
Example alerts for vmalert:
groups:
- name: vm-license
# note the `job` label and update accordingly to your setup
rules:
- alert: LicenseExpiresInLessThan30Days
expr: vm_license_expires_in_seconds < 30 * 24 * 3600
labels:
severity: warning
annotations:
summary: "{{ $labels.job }} instance {{ $labels.instance }} license expires in less than 30 days"
description: "{{ $labels.instance }} of job {{ $labels.job }} license expires in {{ $value | humanizeDuration }}.
Please make sure to update the license before it expires."
- alert: LicenseExpiresInLessThan7Days
expr: vm_license_expires_in_seconds < 7 * 24 * 3600
labels:
severity: critical
annotations:
summary: "{{ $labels.job }} instance {{ $labels.instance }} license expires in less than 7 days"
description: "{{ $labels.instance }} of job {{ $labels.job }} license expires in {{ $value | humanizeDuration }}.
Please make sure to update the license before it expires."