### Describe Your Changes
[vmanomaly docs](https://docs.victoriametrics.com/anomaly-detection/)
update for changes, introduced in v1.13.0
### Checklist
The following checks are **mandatory**:
- [x] My change adheres [VictoriaMetrics contributing
guidelines](https://docs.victoriametrics.com/contributing/).
(cherry picked from commit 1feb5d04d7)
14 KiB
| sort | weight | title | menu | aliases | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 4 | FAQ |
|
|
FAQ - VictoriaMetrics Anomaly Detection
What is VictoriaMetrics Anomaly Detection (vmanomaly)?
VictoriaMetrics Anomaly Detection, also known as vmanomaly, is a service for detecting unexpected changes in time series data. Utilizing machine learning models, it computes and pushes back an "anomaly score" for user-specified metrics. This hands-off approach to anomaly detection reduces the need for manual alert setup and can adapt to various metrics, improving your observability experience.
Please refer to our guide section to find out more.
Note:
vmanomalyis a part of enterprise package. You need to get a free trial license for evaluation.
What is anomaly score?
Among the metrics produced by vmanomaly (as detailed in vmanomaly output metrics), anomaly_score is a pivotal one. It is a continuous score > 0, calculated in such a way that scores ranging from 0.0 to 1.0 usually represent normal data, while scores exceeding 1.0 are typically classified as anomalous. However, it's important to note that the threshold for anomaly detection can be customized in the alert configuration settings.
The decision to set the changepoint at 1.0 is made to ensure consistency across various models and alerting configurations, such that a score above 1.0 consistently signifies an anomaly, thus, alerting rules are maintained more easily.
Note:
anomaly_scoreis a metric itself, which preserves all labels found in input data and (optionally) appends custom labels, specified in writer - follow the link for detailed output example.
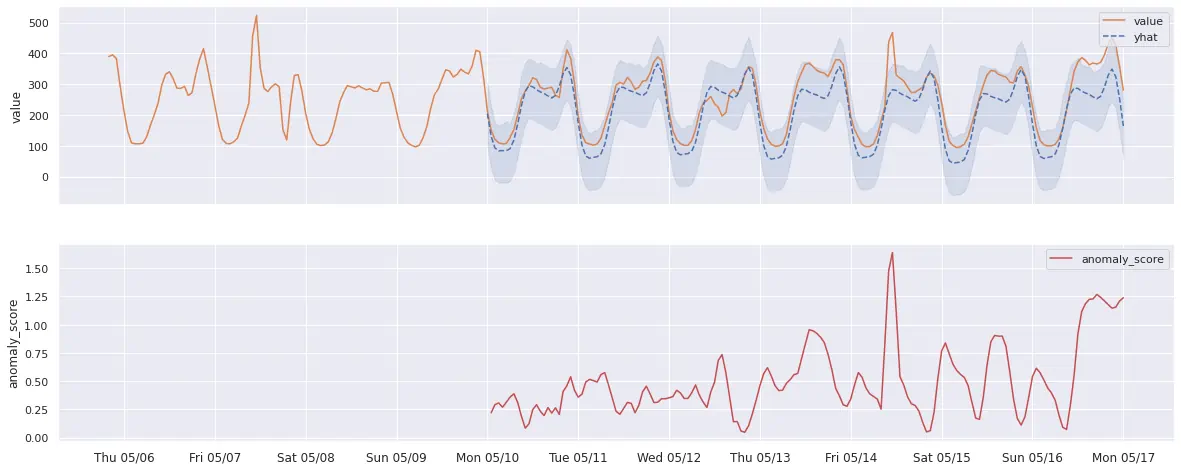
How is anomaly score calculated?
For most of the univariate models that can generate yhat, yhat_lower, and yhat_upper time series in their output (such as Prophet or Z-score), the anomaly score is calculated as follows:
- If
yhat(expected series behavior) equalsy(actual value observed), then the anomaly score is 0. - If
y(actual value observed) falls within the[yhat_lower, yhat_upper]confidence interval, the anomaly score will gradually approach 1, the closeryis to the boundary. - If
y(actual value observed) strictly exceeds the[yhat_lower, yhat_upper]interval, the anomaly score will be greater than 1, increasing as the margin between the actual value and the expected range grows.
Please see example graph illustrating this logic below:
How does vmanomaly work?
vmanomaly applies built-in (or custom) anomaly detection algorithms, specified in a config file. Although a single config file supports one model, running multiple instances of vmanomaly with different configs is possible and encouraged for parallel processing or better support for your use case (i.e. simpler model for simple metrics, more sophisticated one for metrics with trends and seasonalities).
- For more detailed information, please visit the overview section.
- To view a diagram illustrating the interaction of components, please explore the components section.
What data does vmanomaly operate on?
vmanomaly operates on data fetched from VictoriaMetrics, where you can leverage full power of MetricsQL for data selection, sampling, and processing. Users can also apply global filters for more targeted data analysis, enhancing scope limitation and tenant visibility.
Respective config is defined in a reader section.
Handling noisy input data
vmanomaly operates on data fetched from VictoriaMetrics using MetricsQL queries, so the initial data quality can be fine-tuned with aggregation, grouping, and filtering to reduce noise and improve anomaly detection accuracy.
Output produced by vmanomaly
vmanomaly models generate metrics like anomaly_score, yhat, yhat_lower, yhat_upper, and y. These metrics provide a comprehensive view of the detected anomalies. The service also produces health check metrics for monitoring its performance.
Choosing the right model for vmanomaly
Selecting the best model for vmanomaly depends on the data's nature and the types of anomalies to detect. For instance, Z-score is suitable for data without trends or seasonality, while more complex patterns might require models like Prophet.
Also, starting from v1.12.0 it's possible to auto-tune the most important params of selected model class, find the details here.
Please refer to respective blogpost on anomaly types and alerting heuristics for more details.
Still not 100% sure what to use? We are here to help.
Alert generation in vmanomaly
While vmanomaly detects anomalies and produces scores, it does not directly generate alerts. The anomaly scores are written back to VictoriaMetrics, where an external alerting tool, like vmalert, can be used to create alerts based on these scores for integrating it with your alerting management system.
Preventing alert fatigue
Produced anomaly scores are designed in such a way that values from 0.0 to 1.0 indicate non-anomalous data, while a value greater than 1.0 is generally classified as an anomaly. However, there are no perfect models for anomaly detection, that's why reasonable defaults expressions like anomaly_score > 1 may not work 100% of the time. However, anomaly scores, produced by vmanomaly are written back as metrics to VictoriaMetrics, where tools like vmalert can use MetricsQL expressions to fine-tune alerting thresholds and conditions, balancing between avoiding false negatives and reducing false positives.
How to backtest particular configuration on historical data?
Starting from v1.7.2 you can produce (and write back to VictoriaMetrics TSDB) anomaly scores for historical (backtesting) period, using BacktestingScheduler component to imitate consecutive "production runs" of PeriodicScheduler component. Please find an example config below:
schedulers:
scheduler_alias:
class: 'backtesting' # or "scheduler.backtesting.BacktestingScheduler" until v1.13.0
# define historical period to backtest on
# should be bigger than at least (fit_window + fit_every) time range
from_iso: '2024-01-01T00:00:00Z'
to_iso: '2024-01-15T00:00:00Z'
# copy these from your PeriodicScheduler args
fit_window: 'P14D'
fit_every: 'PT1H'
models:
model_alias1:
# ...
schedulers: ['scheduler_alias'] # if omitted, all the defined schedulers will be attached
queries: ['query_alias1'] # if omitted, all the defined queries will be attached
# https://docs.victoriametrics.com/anomaly-detection/components/models/#provide-series
provide_series: ['anomaly_score']
# ... other models
reader:
datasource_url: 'some_url_to_read_data_from'
queries:
query_alias1: 'some_metricsql_query'
sampling_frequency: '1m' # change to whatever you need in data granularity
# other params if needed
# https://docs.victoriametrics.com/anomaly-detection/components/reader/#vm-reader
writer:
datasource_url: 'some_url_to_write_produced_data_to'
# other params if needed
# https://docs.victoriametrics.com/anomaly-detection/components/writer/#vm-writer
# optional monitoring section if needed
# https://docs.victoriametrics.com/anomaly-detection/components/monitoring/
Configuration above will produce N intervals of full length (fit_window=14d + fit_every=1h) until to_iso timestamp is reached to run N consecutive fit calls to train models; Then these models will be used to produce M = [fit_every / sampling_frequency] infer datapoints for fit_every range at the end of each such interval, imitating M consecutive calls of infer_every in PeriodicScheduler config. These datapoints then will be written back to VictoriaMetrics TSDB, defined in writer section for further visualization (i.e. in VMUI or Grafana)
Resource consumption of vmanomaly
vmanomaly itself is a lightweight service, resource usage is primarily dependent on scheduling (how often and on what data to fit/infer your models), # and size of timeseries returned by your queries, and the complexity of the employed models. Its resource usage is directly related to these factors, making it adaptable to various operational scales.
Note
: Starting from v1.13.0, there is a mode to save anomaly detection models on host filesystem after
fitstage (instead of keeping them in-memory by default). Resource-intensive setups (many models, many metrics, biggerfit_windowarg) and/or 3rd-party models that store fit data (like ProphetModel or HoltWinters) will have RAM consumption greatly reduced at a cost of slightly slowerinferstage. To enable it, you need to set environment variableVMANOMALY_MODEL_DUMPS_DIRto desired location. Helm charts are being updated accordingly (StatefulSetfor persistent storage starting from chart version1.3.0).
Here's an example of how to set it up in docker-compose using volumes:
services:
# ...
vmanomaly:
container_name: vmanomaly
image: victoriametrics/vmanomaly:latest
# ...
ports:
- "8490:8490"
restart: always
volumes:
- ./vmanomaly_config.yml:/config.yaml
- ./vmanomaly_license:/license
# map the host directory to the container directory
- vmanomaly_model_dump_dir:/vmanomaly/tmp/models
environment:
# set the environment variable for the model dump directory
- VMANOMALY_MODEL_DUMPS_DIR=/vmanomaly/tmp/models/
platform: "linux/amd64"
command:
- "/config.yaml"
- "--license-file=/license"
volumes:
# ...
vmanomaly_model_dump_dir: {}
Scaling vmanomaly
Note: As of latest release we don't support cluster or auto-scaled version yet (though, it's in our roadmap for - better backends, more parallelization, etc.), so proposed workarounds should be addressed manually.
vmanomaly can be scaled horizontally by launching multiple independent instances, each with its own MetricsQL queries and configurations:
-
By splitting queries, defined in reader section and spawn separate service around it. Also in case you have only 1 query returning huge amount of timeseries, you can further split it by applying MetricsQL filters, i.e. using "extra_filters" param in reader
-
or models (in case you decide to run several models for each timeseries received i.e. for averaging anomaly scores in your alerting rules of
vmalertor using a vote approach to reduce false positives) - seequeriesarg in model config -
or schedulers (in case you want the same models to be trained under several schedules) - see
schedulersarg model section andschedulercomponent itself
Here's an example of how to split on extra_filters param
# config file #1, for 1st vmanomaly instance
# ...
reader:
# ...
queries:
extra_big_query: metricsql_expression_returning_too_many_timeseries
extra_filters:
# suppose you have a label `region` with values to deterministically define such subsets
- '{region="region_name_1"}'
# ...
# config file #2, for 2nd vmanomaly instance
# ...
reader:
# ...
queries:
extra_big_query: metricsql_expression_returning_too_many_timeseries
extra_filters:
# suppose you have a label `region` with values to deterministically define such subsets
- '{region="region_name_2"}'
# ...