This reduces the size of docs/* folder from 33MB to 18MB
Images inside docs/operator/* must be converted at the https://github.com/VictoriaMetrics/operator/tree/master/docs
and then the updated images must be automatically propagated to the docs/operator/*
This is a follow-up for d3f919df3e
Updates https://github.com/VictoriaMetrics/VictoriaMetrics/pull/5206
3.5 KiB
| sort | weight | title | menu | aliases | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 31 | 31 | VictoriaMetrics Cluster Per Tenant Statistic |
|
|
VictoriaMetrics Cluster Per Tenant Statistic
The per-tenant statistic is a part of enterprise package. It is available for download and evaluation at releases page. You need to request a free trial license for evaluation.
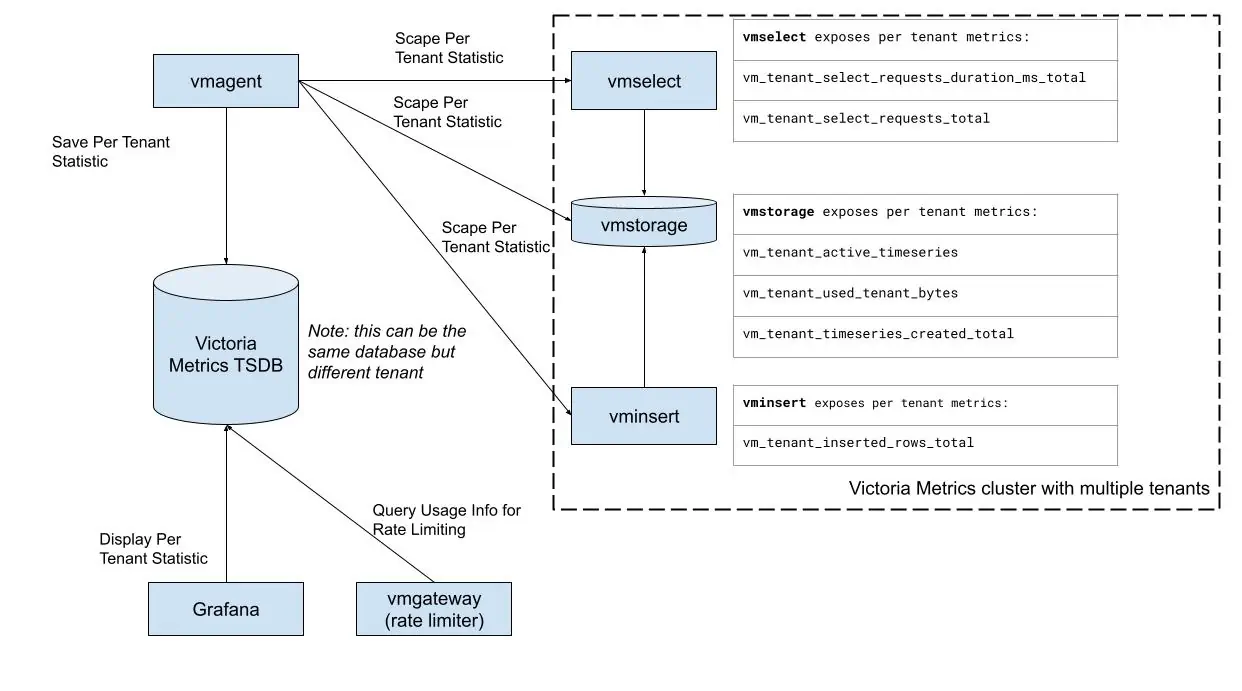
VictoriaMetrics cluster for enterprise provides various metrics and statistics usage per tenant:
-
vminsertvm_tenant_inserted_rows_total- total number of inserted rows. Find out which tenant puts the most of the pressure on the storage.
-
vmselectvm_tenant_select_requests_duration_ms_total- query latency. Helps to identify tenants with the heaviest queries.vm_tenant_select_requests_total- total number of requests. Discover which tenant sends the most of the queries and how it changes with time.
-
vmstoragevm_tenant_active_timeseries- number of active time series. This metric correlates with memory usage, so can be used to find the most expensive tenant in terms of memory.vm_tenant_used_tenant_bytes- disk space usage. Helps to track disk space usage per tenant.vm_tenant_timeseries_created_total- number of new time series created. Helps to track the churn rate per tenant, or identify inefficient usage of the system.
Collect the metrics by any scrape agent you like (vmagent, victoriametrics, Prometheus, etc) and put into TSDB.
It is ok to use existing cluster for storing such metrics, but make sure to use a different tenant for it to avoid collisions.
Or just run a separate TSDB (VM single, Prometheus, etc.) to keep the data isolated from the main cluster.
Example of the scraping configuration for statistic is the following:
scrape_configs:
- job_name: cluster
scrape_interval: 10s
static_configs:
- targets: ['vmselect:8481','vmstorage:8482','vminsert:8480']
Visualization
Visualisation of statistics can be done in Grafana using the following dashboard.
Integration with vmgateway
vmgateway supports integration with Per Tenant Statistics data for rate limiting purposes.
More information can be found here
Integration with vmalert
You can generate alerts based on each tenant's resource usage and send notifications to prevent limits exhaustion.
Here is an alert example for high churn rate by the tenant:
{% raw %}
- alert: TooHighChurnRate
expr: |
(
sum(rate(vm_tenant_timeseries_created_total[5m])) by(accountID,projectID)
/
sum(rate(vm_tenant_inserted_rows_total[5m])) by(accountID,projectID)
) > 0.1
for: 15m
labels:
severity: warning
annotations:
summary: "Churn rate is more than 10% for the last 15m"
description: "VM constantly creates new time series in the tenant: {{ $labels.accountID }}:{{ $labels.projectID }}.\n
This effect is known as Churn Rate.\n
High Churn Rate is tightly connected with database performance and may
result in unexpected OOM's or slow queries."
{% endraw %}